Search results for jogging easily
Spiral Linux: A Reliable Distribution with Powerful Data Recovery Tool

Spiral Linux is a Debian-based distribution that offers a range of desktop environments, making it stand out from other Linux distributions. In addition, it comes with a unique tool called SnapperGUI , which simplifies the process of creating operating system snapshots. These snapshots serve as a data recovery solution, allowing users to revert to a previously working state easily.
Data Recovery Debian-based distribution Powerful Data Spiral Linux
Spiral Linux: A Reliable Distribution with Powerful...
Spiral Linux is a Debian-based distribution that offers a range of desktop environments,...
Source: LinuxSecurity.com
Password Management and Protection - Part 1: The Basics

Happy World Password Day! (In 2024, it's being celebrated on May 2nd). Remembering loads of passwords is an absolute pain. As we work in corporate jobs, we find that the number of personal and professional passwords we have continues to grow, along with having to log into systems numerous times a day. In general, employees manage 191 logins and login 154 times a month, with each login taking, on average, 14 seconds, causing us to spend at least 36 minutes entering passwords per month. Let's look at why a password manager should take care of it rather than tracking them all in our heads or on a scrap of paper. The Impact of a Data Breach According to Statista's report, 6.43 million data records were leaked during the first quarter of 2023. When these data breaches occur, the leaked data may include our email addresses and passwords. This breach can start a chain reaction of "bad actors" accessing our accounts, locking us out, and gaining access to further accounts if they have access to the email account. This exploit can further snowball if the same password is used on all accounts. The "bad actor" can gain access to our email. They use the email information to understand the services we're signed up for and access them using the same password. n Using the same password across accounts is like using the one key for all the locks in an entire town and having thieves steal the key. They can then go through the contents of every building, see what is there, vandalize, and steal whatever they want. The impact financially and mentally would be huge. Detecting Data Breaches Google One provides scanning for our email addresses on the dark web, which lets us know the data breaches where our email addresses were exposed. The website Have I Been Pwned (HIBP) allows us to check on any email address and see if it's been exposed through a data breach. There are also complete identity monitoring services that keep track of our email addresses, banking details, passport information, driving license, and social security numbers. These complete services usually come at a cost. Protecting Users From Data Breaches HIBP provides a free service to check if a user's password has been compromised in a data breach. The HIBP API can be integrated into the sign-in or password update services to notify users that the password has been compromised. Ideally, when updating a password with a known compromised password, the service would block that password from being used with helpful information. HIBP doesn't publish the companies that use the API on their platforms, but as users, we can ask for the platforms to have this feature, and if we're in the privileged position of creating the applications, we can work to include this feature. Why Do We Need a Good Password? Along with the data breaches that may show our passwords on the dark web, hackers also try to break into our accounts by using software to guess our passwords. Below, we can see that the simpler the password is regarding character type, the easier it is to crack, even when the password length is increased. n However, suppose we use a previously stolen password, simple words, or the same password across multiple sites. In that case, the table above will turn purple as each password will be forced instantly, no matter the character combination or length. This scenario is because hackers will start with standard, easy, or already-known passwords rather than from scratch. Why Do We Re-Use Passwords? Remembering long and complex passwords is tricky unless we have a photographic memory like Sheldon Cooper from The Big Bang Theory. Generally, we need to have memorable passwords, and having so many accounts with the ever-increasing number of accounts we use, it's tricky to keep track of all the passwords. Some strategies to deal with this are to reuse passwords or have a base password that slightly changes based on the name of the service being used. In the 2021 report from LastPass, 92% of people know that re-using the same password or a variation is a risk. However, more than learning is needed to cause people to take action. Good Security Practices According to Bitwarden, the six good security practices we need are: Check if our password has been pwned: we are checking to see if the password has been exposed in a data breach. Ensure that we have a strong password: if we don't have a password manager that provides a password generator, we could use Bitwarden's strong password generator to create a password. If we have a password that we think is strong and want to check it, we could use Security.org's password checker. Embrace two-factor authentication: a report by Comparitech says that 99.9% of all attacks are blocked by multi-factor authentication (MFA). For the small percentage that MFA doesn't block, hackers will use social engineering, MFA fatigue, or other means to obtain the additional form of authentication needed. Stick to encrypted sharing methods: using our password manager's sharing facility is an excellent way to go. Avoid re-use altogether: update the passwords for any accounts where our password has been re-used. Use a password manager: Techradar has a good review for 2024 that compares password managers and recommends them for different life scenarios. Taking Password Management Seriously Using a password manager is a way to strengthen our password security, remove the cognitive load of remembering all our passwords, and speed up our ability to log into platforms and services. The National Cyber Security Centre in the UK defines it as: A password manager is an app on your phone, tablet or computer that stores your passwords, so you don't need to remember them Along with storing the password, a good password manager makes it frictionless to enter, lets us know if a password is re-used or weak, alerts us if our password has been compromised, and can manage our second-factor authentication. The password manager can also sync the passwords across all the platforms we need to enter our passwords. According to a 2022 Security.org report, users who do not use password managers are three times more likely to experience identity theft than those who do. Application Password Security Over time, applications have become more sophisticated in how they store passwords. Initially, they might have been stored in plain text in the database, but now they are transformed by a process that cannot be reversed. Over time, these transformation processes are getting more sophisticated. In a data breach, the leaked passwords should be the transformed version, so this slows down "bad actors" as they try to figure out how the passwords have been transformed, and the transformation takes time. To speed the process up, they will take known passwords that have been transformed and see if they match what has been leaked, as they will be immediately able to enter those accounts. This is why we must change our passwords after a data breach and ensure they are different across accounts. If we have a good password, it slows them down from cracking it and gives us time to change it before they access our account. What Password Manager Should We Use? Some free password managers are iCloud Keychain, Google Password Manager, and Firefox Password Manager. These are a good start; however, they have limitations and are tied to the browser they are associated with. This means the iCloud keychain works with Safari, Google Password Manager with Chrome, and Firefox Password Manager with Firefox. Suppose we're finding that we need to enter passwords outside of our browser and have to try and find the password, or we are defaulting back to inadequate password behaviors. In that case, it may be time we looked into dedicated password managers. When looking for a password manager, we should look for one that easily syncs across all devices and makes it easy to save and enter our passwords at a minimum. Once we have entered our password for the password manager or used our fingerprint, for example, to log in, we should be able to choose in one click which accounts we want to use to log into a service. Some password managers will automatically enter our credentials in the app or website. A reputable review site can save us the hard work of comparing the different services. An example is the Techradar review for 2024. On the list, there are free and paid solutions. Starting Our Life With a Password Manager Once we've chosen our password manager, we must enable our devices and browsers to use it seamlessly. This might be apps or browser extensions. Let's take Bitwarden and 1Password as our examples since Bitwarden is currently the best free password manager available, according to TechRadar, while 1Password is used by many businesses. We need to install the apps and extensions to get started using them. Both websites provide handy download pages: Bitwarden: https://bitwarden.com/download 1Password: https://1password.com/downloads At the end of installing everything, we should have the following: A desktop app Extensions for each browser we use, e.g. Chrome, Safari, Edge… The mobile app When setting up the mobile app for Bitwarden, they have a help page on setting up autofill and unlocking using biometrics, as they are necessary to make using the app as easy as possible. Password Checkup Some password managers will provide a service to score all our passwords and let us know where we may be exposed. 1Password provides Watchtower, which identifies the following: Identify vulnerable logins imported from LastPass: LastPass had data breaches, and this check informs us where we might be vulnerable. Find compromised websites and vulnerable passwords. Find websites that support passkeys. Identify re-used and weak passwords. Find unsecured websites. Identify logins that support two-factor authentication. Check for expiring items Find duplicate items. Ideally, we want a perfect score across the board, but the reality is that we can do what the websites allow us to do. This means that any accounts that limit us to having PINs or short passwords will either show up as being vulnerable or having a weak password. In these cases, we need to ensure that if there are any second forms of authentication, we have them enabled so that if a hacker blows their way through, they are blocked by MFA, which we read blocks hackers 99.9% of the time. Banks are notorious for having very weak password or PIN protocols, and they must combine them with apps, one-time passcodes, and card readers. One-Time Passcodes Another feature our password manager hopefully has is the ability to store one-time passcodes. These are a form of second-factor authentication, set up by scanning a QR code. Once set up, the codes change every thirty seconds. The benefit of having them in our password manager is that they are automatically entered when needed rather than being retrieved from another app. 1Password has a guide to help us through the process of setting up one-time passcodes. What's next? Since it's World Password Day, we can level up our password management skills and ensure we're not vulnerable. If we don't have a password manager, it's an opportunity to set one up, as it's easy and will save us time. We can bite the bullet and change any re-used passwords. Also, look at our vulnerable and weak passwords in our password manager and tackle a few of them. Over time, we can improve our password management score. Conclusion Password management is a problem that we all have to tackle. Keeping track of passwords in our heads and coming up with unique, strong passwords is challenging. Rather than having this cognitive load, we've seen the benefit that password managers bring. The only question left is, what will it take us to make the simple move of setting up our password manager and living the life of not having to remember loads of passwords and instead our one password manager password? Further Reading 139 password statistics to help you stay safe in 2024: https://us.norton.com/blog/privacy/password-statistics References LastPass Reveals 8 Truths about Passwords in the New Password Exposé: https://blog.lastpass.com/posts/2017/11/lastpass-reveals-8-truths-about-passwords-in-the-new-password-expose Data Breaches Worldwide: https://www.statista.com/topics/11610/data-breaches-worldwide/#topicOverview Google One Dark Web Report: https://one.google.com/dwr/dashboard Have I Been Pwned: https://haveibeenpwned.com Have I Been Pwned Password Checker: https://haveibeenpwned.com/Passwords Have I Been Pwned Password API: https://haveibeenpwned.com/API/v3#PwnedPasswords Bitwarden's Strong Password Generator: https://bitwarden.com/password-generator Password Manager tips from the National Cyber Security Centre in the UK: https://www.ncsc.gov.uk/collection/top-tips-for-staying-secure-online/password-managers Hive Tech Password: https://www.hivesystems.com/password The 2021 Psychology of Passwords Report: https://www.lastpass.com/resources/ebook/psychology-of-passwords-2021 6 Things to Keep Your Passwords Secure: https://bitwarden.com/blog/6-things-to-keep-your-passwords-secure Password Statistics: https://www.comparitech.com/blog/information-security/password-statistics 3 Techniques to Bypass MFA: https://securityscorecard.com/blog/techniques-to-bypass-mfa Password Manager Annual Report 2022: https://www.security.org/digital-safety/password-manager-annual-report/2022 Best Password Manager of 2024: https://www.techradar.com/best/password-manager Password Manager Mobile Apps: https://bitwarden.com/help/getting-started-mobile Use Watchtower to find the account details you need to change: https://support.1password.com/watchtower/ Setting up one-time passcodes in 1Password: https://support.1password.com/one-time-passwords/ Credits The title image is from Dreamstudio AI.
Password Management and Protection - Part 1: The Basics...
Happy World Password Day! (In 2024, it's being celebrated on May 2nd). Remembering...
Source: Hacker Noon
Is It Game Over for Cheaters? Using Blockchain Technology to Eliminate Unwanted Gaming Behavior

When in-game cheating becomes the norm, does the gaming industry have a major problem on its hands? A global study of the gaming industry would say yes. It was found that 77% of online gamers are likely to stop playing a multiplayer game online if they think other players are cheating, and 48% of online gamers are likely to buy less in-game content. Add in the accrued value of digital assets as a key feature of blockchain gaming, and developers have an obligation to tackle this problem head-on. An attractiveness to bending the rules is not something limited to the world of online gaming; it is rife in all parts of society. However, as social psychologist Corey Butler points out ‘anonymity (playing with strangers or online) and opportunity can tip the scales toward greater cheating. When strong incentives like money or grades are on the line, otherwise honest people might be tempted to cheat. If somebody with a competitive nature is presented with the opportunity to easily outperform the other at a task, then it's safe to say that many will bite the bullet and risk the reward for the easy win—factor in the monetary value of rewards in Web3 gaming, and this desire to win increases significantly. However, when it comes to multiplayer online games, the competition is designed around entertainment, fun, and the community. These core values of gaming make cheating a stain on the industry as a whole. Cheating is the new norm. Cheating in some of the largest games has become an economy of its own, with many platforms and YouTube channels dedicated to introducing cheating, hacks, and navigating the ways to cheat. Don't believe us, simply type fortnite cheat terms into a google search. Combating this trend is critical for maintaining the reputation of these brands. Simon Vieira, CEO of MixMob, a Solana-based gaming platform, believes the temptation to cheat is rife, but it is nothing new, “Web3 games offer enhanced incentives due to the tangible value of game coins and digital items. However, this also creates a greater temptation to cheat. That said, traditional gaming has previously addressed similar issues. For instance, real money gaming employs methods such as biotic randomness to obscure certain game aspects like matchmaking. This approach reduces predictability, thus diminishing the incentives to cheat while still maintaining a skill-based gaming environment. We apply these strategies at MixMob to ensure fairness and keep the game engaging for all players,” says Vieira. When hacking games, cheaters now have an endless stack of tools to choose from when it comes to infiltrating game mechanics with glitching and farming to using aimbots in the software and speed hacks. This problem is exacerbated in Web3 gaming as it lacks an authoritative host. “Fair play is crucial in multi-player games as it directly impacts player engagement and retention. A fair environment ensures that players feel valued and that the game remains competitive and enjoyable for everyone,” notes Vieira. Furthermore, with AI, it is easier than ever to predict patterns of player behavior and create new ways to exploit and manipulate gaming data. So, how can this problem be addressed without compromising the gaming experience? Speaking to Tashi Protocol CEO Sandeep Bhatia, it is clear that consensus will play a future role in blockchain gaming. “Dynamite as the network transport for multiplayer games can prevent certain forms of cheating like 'lag switching' or local state hacking. The benefit of having consensus on top of a peer-to-peer network layer ensures that players cannot cheat, and the architecture reduces costs.” Frustration with the publishers Publishers are tackling the issue of one player, or several players at a time, by banning them and using anti-cheat software. Just last month, Activision, a gaming giant and creator of Call of Duty, banned 27,000 accounts from the game. However, this isn't deterring new cheats coming into the sector. Tackling it from the outset in the process of the game studio is the only way to ensure that both the publishers and the gamers benefit in the long run. To restore confidence, creators of blockchain games must demonstrate trust from the outset. “Shifting from a traditional gaming infrastructure to adopt a decentralized, serverless framework will optimize the entire Web3 gaming experience and solve the issue of cheating from the ground up. Not only can we reduce the costs by eliminating the need for centralized servers, but Tashi's Dynamite ensures fair distribution and protection against common security threats,” says Bhatia. Once a player sees that a game is compromised, it ruins the fun element and may even deter them from entering the environment because of security fears. In addition, the influx of bots and other hacks has led to unfair advantages within some of the most loved games. What can blockchain game publishers do? Gaming studios must take the necessary steps to demonstrate their commitment to fair play. This is essential in the blockchain space as it continues to build trust with the traditional gaming communities. At MixMob, they leverage blockchain transparency to allow the community to participate in monitoring and reporting cheaters actively. “This community refereeing not only helps maintain fairness but also fosters a sense of responsibility and integrity among players, and it has worked great for us,” says Vieira. “Web3 game publishers must take decisive steps to limit cheating. The actions taken should vary based on the severity of the cheating incident. Potential measures include banning, suspending, or permanently removing players involved in unfair practices. Additionally, publishers can adopt proven strategies from traditional gaming, such as introducing randomness to some parts of the game to reduce predictability, which helps deter cheating,” he continues. Game developers who are keen to implement anti-cheat measures are often outplayed by hackers who have mastered the art of cheating and the avoidance of detection. Sure, developers can ban cheaters who are caught in the act or embed cheat detection software. However, this doesn't prevent cheating from occurring from the outset. The vulnerabilities have already been exploited by the time the developer has their hands on the activities. If, however, a game creator starts the development process using the Tashi Consensus Protocol, it has eliminated the act of cheating from the initial design stage. “Gamers rely on trust that game developers would have implemented the best practices to ensure cheaters are punished. That is why Tashi works to educate all its gaming partners on the novel ways blockchain solves cheating issues. We make our tech easy to use and guide all our partners who might come from the Web2 world and are new to using blockchain tech,” added Bhatia. While anti-cheat software like Riot Game's Vanguard or Activision Blizzard's Ricochet stands as the frontline defense, the second layer can utilize the transparency provided by blockchain technology to fight against bad actors. Implementing innovative approaches to game development, like the Tashi Dynamite Consensus Engine, pushes gaming to a new era of fair play and reclaims the values that true gamers want to see in the game development stage. In addition to fostering a culture of fair play, a paradigm shift is necessary in the approach to combating cheating in online gaming. By 2027, the number of users in the Online Games market is expected to amount to 1.2bn users. The projected revenue in the Online Games market worldwide is expected to reach US.97bn in 2024. Reclaiming the gaming sector for true gamers who value the entire gaming experience is crucial as blockchain games position themselves alongside some of the gaming giants. n
Is It Game Over for Cheaters? Using Blockchain Technology...
When in-game cheating becomes the norm, does the gaming industry have a major problem...
Source: Hacker Noon
Belgium Cybersec Community (Be.Cyber)

Join the Be.Cyber community! On the program: news and tools monitoring, mutual aid and knowledge sharing, event organization (workshops, CTF resolution), ... And it's all in good fun!
Belgium Cybersec Community (Be.Cyber)
Join the Be.Cyber community! On the program: news and tools monitoring, mutual aid...
The Five W's for Setting KPIs
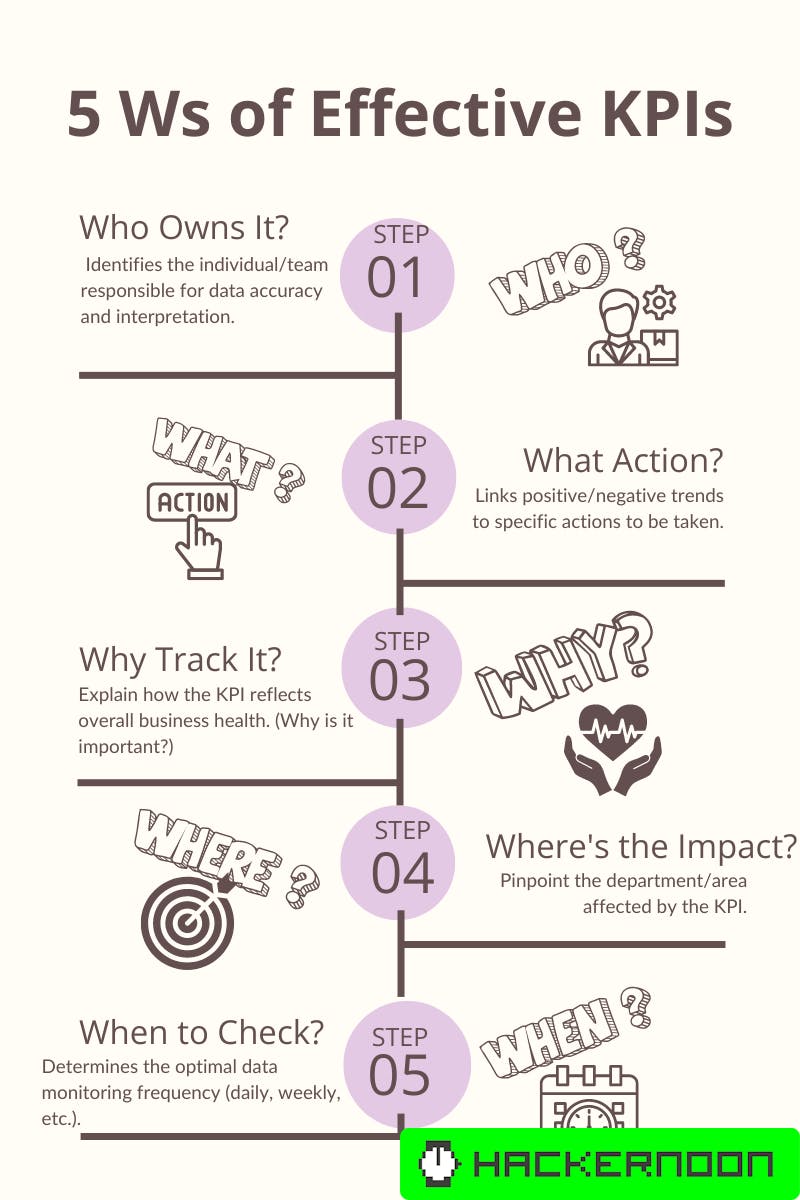
Many leaders envision a data strategy as a readily available buffet - a vast collection of metrics that can be easily assembled into insights. This approach overlooks a critical first step: defining clear and actionable Key Performance Indicators (KPIs). These KPIs serve as the foundation for your data strategy, guiding you towards the metrics that matter.
easily assembled leaders envision Performance Indicators Setting KPIs vast collection
The Five W's for Setting KPIs
Many leaders envision a data strategy as a readily available buffet - a vast collection...
Source: Hacker Noon
Never Rely on UUID for Authentication: Generation Vulnerabilities and Best Practices

UUID for authentication There is hardly a person nowadays who never clicked that "Recover password" button in deep frustration. Even if it does seem the password was without a doubt correct, the next step of recovering it mostly goes smoothly with visiting a link from an email and entering the new password (let's not fool anyone; it is hardly new as you have just typed it three times already in step 1 before pressing the obnoxious button). The logic behind email links, however, is something to take great scrutiny about as leaving its generation insecure opens a flood of vulnerabilities regarding unauthorized access to user accounts. Unfortunately, here is one example of a UUID-based recovery URL structure many probably encountered, which does not nevertheless follow security guidelines: https://.../recover/d17ff6da-f5bf-11ee-9ce2-35a784c01695 If such a link is used, it generally means that anyone can get your password, and it is as simple as that. This article aims to dive deep into UUID generation methods and select insecure approaches to their application. What is UUID UUID is a 128-bit label commonly used in generating pseudo-random identifiers with two valuable attributes: it is complex enough and unique enough. Mostly, those are key requirements for ID leaving the backend and being shown to the user explicitly in the frontend or generally sent over API with the ability to be observed. It makes one hard to guess or brute-force in comparison to id = 123 (complexity) and prevents collisions when the generated id is duplicated to previously used, e.g., a random number from 0 to 1000 (uniqueness). The "enough" parts actually come from, firstly, some versions of Universally Unique IDentifier, leaving it open for minor possibilities for duplications, which is, however, easily mitigated by additional comparison logic and does not pose a threat due to hardly controlled conditions for its occurrence. And secondly, the take on complexity of various UUID versions is described in the article, in general it is assumed to be quite good except for further corner cases. Implementations in backend Primary keys in database tables appear to rely on the same principles of being complex and unique as UUID does. With the wide adoption of built-in methods for its generation in many programming languages and database management systems, UUID often comes as the first choice to identify data entries stored and as a field to join tables in general and subtables split by normalization. Sending user IDs that come from a database over API in response to certain actions is also common practice for making a process of unifying data flows simpler without extra temporary ID generation and linking them to ones in production data storage. In terms of password reset examples, the architecture more likely includes a table responsible for such an operation that inserts rows of data with generated UUID every time a user clicks the button. It initiates the recovery process by sending an email to the address associated with the user by their user_id and checking which user to reset the password for based on the identifier they have once the reset link is opened. There are, however, security guidelines for such identifiers visible to users, and certain implementations of UUID meet them with varying degrees of success. Outdated versions Version 1 of UUID generation splits its 128 bits into using a 48-bit MAC address of the device generating identifier, a 60-bit timestamp, 14-bit stored for incrementing value, and 6 for versioning. Uniqueness guarantee is thus transferred from rules in code logic to hardware manufacturers who are supposed to assign values for every new machine in production correctly. Leaving only 60+14 bits to represent useful changeable payload deteriorates the integrity of the identifier, especially with such transparent logic behind it. Let's take a look at a sequence of consequently generated number of UUID v1: from uuid import uuid1 for _ in range(8): print(uuid1()) d17ff6da-f5bf-11ee-9ce2-35a784c01695 d17ff6db-f5bf-11ee-9ce2-35a784c01695 d17ff6dc-f5bf-11ee-9ce2-35a784c01695 d17ff6dd-f5bf-11ee-9ce2-35a784c01695 d17ff6de-f5bf-11ee-9ce2-35a784c01695 d17ff6df-f5bf-11ee-9ce2-35a784c01695 d17ff6e0-f5bf-11ee-9ce2-35a784c01695 d17ff6e1-f5bf-11ee-9ce2-35a784c01695 As can be seen, the "-f5bf-11ee-9ce2-35a784c01695" part stays the same all the time. The changeable part is simply a 16-bit hexadecimal representation of sequence 3514824410 - 3514824417. It is a superficial example as production values are usually generated with more significant gaps in time in between, so the timestamp-related part is also changed. 60-bit timestamp part also means that a more significant part of the identifier is visually changed over a larger sample of IDs. The core point stays the same: UUIDv1 is easily guessed, however random-looking it initially appears. Take just the first and last values from the given list of 8 ids. As identifiers are generated strictly, consequently, it is clear there are only 6 IDs generated between the given two (by subtracting hexadecimal changeable parts), and their values can also be definitively found. Extrapolation of such logic is the underlying part behind the so-called Sandwich attack aiming to brute-force UUID from knowing these two border values. Attack flow is straightforward: the user generates UUID A before the target UUID generation occurs and UUID B right after. Assuming the same device with a static 48-bit MAC part is responsible for all three generations, it sets a user with a sequence of potential IDs between A and B, where the target UUID is located. Depending on the time proximity between generated IDs to target, the range can be in volumes accessible to brute-force approach: check every possible UUID to find existing ones among empty. In API requests with the password recovery endpoint described previously, it translates to sending hundreds or thousands of requests with consequent UUIDs until a response stating the existing URL is found. With password reset, it leads to a setup where the user can generate recovery links on two accounts they control as closely as possible to press the recovery button on the target account they have no access to but only knows email/login. Letters to controlled accounts with recovery UUIDs A and B are then known, and the target link to recover the password for the target account can be brute-forced without having access to the actual reset email. Vulnerability originates from the concept of relying solely on UUIDv1 for user authentication. By sending a recovery link that grants access to resetting passwords, it is thus assumed that by following the link, a user is authenticated as the one who was supposed to receive the link. This is the part where the authentication rule fails due to UUIDv1 being exposed to straightforward brute force in the same way as if someone`s door could be opened by knowing what the keys of both their neighbor doors look like. Cryptographically insecure functions The first version of UUID is mainly considered legacy partly because generation logic only uses a smaller portion of identifier size as a randomized value. Other versions, like v4, try to solve this issue by keeping as little space as possible for versioning and leaving up to 122 bits to be random payload. In general, it brings total possible variations to a whooping 2^122, which for now is considered to satisfy the "enough" part regarding identifier uniqueness requirement and thus fulfill security standards. Opening for brute-force vulnerability might appear if generation implementation somehow significantly diminishes the bits left for the random part. But with no production tools or libraries, should that be the case? Let's indulge in cryptography a bit and take a close look at JavaScript's common implementation of UUID generation. Here is randomUUID() function relying on math.random module for pseudo-random number generation: Math.floor(Math.random()*0x10); And the random function itself, for short it is just the part of interest for the topic in this article: hi = 36969 * (hi & 0xFFFF) + (hi >> 16); lo = 18273 * (lo & 0xFFFF) + (lo >> 16); return ((hi << 16) + (lo & 0xFFFF)) / Math.pow(2, 32); Pseudo-random generation requires seed value as a base to perform mathematical operations on top of it to produce sequences of random enough numbers. Such functions are solely based on it, meaning that if they are reinitialized with the same seed as before, the output sequence is going to match. The seed value in the JavaScript function in question comprises variables hi and lo, each a 32-bit unsigned integer (0 through 4294967295 decimal). A combination of both is needed for cryptographic purposes, making it close to impossible to definitively reverse the two initial values by knowing their multiple, as it relies on the complexity of integer factorization with large numbers. Two 32-bit integers together bring 2^64 possible cases for guessing hi and lo variables behind the initialized function producing UUIDs. If hi and lo values are somehow known, it takes no effort to duplicate the generation function and know all the values it produces and will produce in the future due to seed value exposure. However, 64 bits in security standards can be considered intolerant to brute-force in a measurable time period for it to make sense. As always, the issue comes from specific implementation. Math.random() takes various 16 bits from each of hi and lo into 32-bit results; however, randomUUID() on top of it shifts the value once again due to .floor() operation, and the only meaningful part all of a sudden now comes exclusively from hi. It does not affect generation in any way but causes cryptography approaches to fall apart as it only leaves 2^32 possible combinations for the entire generation function seed (there is no need to brute-force both hi and lo as lo can be set to any value and does not influence the output). Brute-force flow consists of acquiring a single ID and testing possible high values that could have generated it. With some optimization and average laptop hardware, it can take just a couple of minutes and does not require sending lots of requests to the server as in the Sandwich attack but rather performs all operations offline. The result of such an approach causes replication of the generation function state used in the backend to get all created and future reset links in the password recovery example. Steps to prevent vulnerability from emerging are straightforward and shout out for the use of cryptographically secure functions, e.g. crypto.randomUUID(). Takeaways UUID is a great concept and makes the lives of data engineers a lot easier in many application areas. However, it should never be used in relation to authentication, as in this article, flaws in certain cases of its generation techniques are brought to light. It obviously does not translate to the idea of all UUIDs being insecure. The basic approach, though, is to persuade people not to use them for security at all, which is more efficient and, well, secure than setting complex limits in documentation on which to use or how not to generate them for such purpose.
Never Rely on UUID for Authentication: Generation...
UUID for authentication
There is hardly a person nowadays who never clicked that...
Source: Hacker Noon
How to Power up your Digital Marketing with Deep Learning Predictions

“We're at the beginning of a golden age of AI and are solving problems that were once in the realm of science fiction.” Jeff Bezos Today, 83% of organizations worldwide cite AI as a top priority, with the AI market projected to surge twentyfold by 2030. Amidst intensifying competition, it makes sense that businesses do not dare disregard AI technologies anymore. So it's quite disappointing to many that, despite certain advancements in digital marketing, ad campaigns continue to fall short of optimal efficiency, with ad investments yielding subpar returns, campaigns failing to meet benchmarks and KPIs, and ROIs proving challenging to gauge. Disrupting Traditional Advertising with the Power of AI Over the years, companies have accumulated a significant amount of raw data – a true goldmine of marketing insights that is often underutilized and undervalued. After investing in ad campaigns, businesses gained a better understanding of their customers and their needs. However, many of them have not yet learned how to effectively monetize that data. To increase profits, companies started paying more attention to higher-margin indicators. This has led to the layoff of redundant employees and the automation of work processes. Multinationals and tycoons like Tesla are investing significant resources in robotics and automation to minimize errors in production and reduce labor costs, which are rising due to inflation. Traditional media advertising has become less effective due to information saturation and banner blindness. Therefore, companies are actively working on personalization and targeted advertising to increase conversion rates and campaign efficiency. As a result, businesses are investing more in user acquisition, but their returns need to be secured. For companies with high stakes and narrow user segments, analytics and historical user activity data can help identify which users bring in more profits and how to acquire them more efficiently. This way, they can fine-tune their advertising campaigns and improve performance marketing metrics. In the context of rising costs on auction platforms like Google and Meta, companies are facing increased click costs and competition. Therefore, it's important to understand how quickly user acquisition investments can be recouped. Analytics solutions like Lemon AI can help companies determine the payback period and make informed decisions on scaling or adjusting their ad budgets. How this actually works Let's take a look at two scenarios that are taking place in the market. You have a large number of purchases from a very wide target audience, with some users bringing you more revenue and staying with you longer than others. Still, you pay more or less the same average price for all users from your wide audience, even though their lifetime value and retention rate can vary significantly. This, of course, makes your campaigns less efficient than they could be. So, it's reasonable to want to optimize your spending, considering the potential profitability of each user. That's why it's crucial to segment your audience based on how much each segment will bring you in the future. Based on this information, you can pay different amounts for different segments depending on their predictive value. For example, it could be for users from segment A that will bring you to , .5 for users from segment B that will bring you to , and for users from segment C with over of potential lifetime value. Imagine you have very few target users, and you need to find users who are similar to your current paying audience but have not made a purchase yet. In this case, you would want to expand your audience. The challenge here is that with very few events happening, it's difficult to promptly identify the users you need. What we can do here is leverage our predictions built for an audience as similar as possible; as a result, your user acquisition source gets much more knowledge about target users to be attracted and can be easily optimized based on this knowledge. If historically you've had, let's say, only 1% of users who make purchases, increasing your conversion rate to just 5% is already a significant improvement that has a great impact on your revenues. It's important to note that the effectiveness of solving these problems always depends on mathematics and data processing methods. There are numerous data collection methods, but not all companies have learned how to analyze and monetize them correctly. Understanding which methods and approaches work best for a specific industry can give companies an advantage and help them achieve better results. Making your Ad Campaigns Shine The first step here is defining the goal of your campaign. For example, if you want to introduce a new product, whether it's a new game or a fitness app, your initial objective would be to create brand awareness so that people start spreading the word. To get there, you can use various media channels like Display & Video 360 (DV360) or Display Network (GDN) by Google, where you search to optimize expenses for the most efficient audience acquisition. Next, it comes down to User Acquisition (UA) and Performance, and here we have two essential questions. First, how do we find the optimal marketing mix using various channels? For instance, efficiently allocating your ad budget across different channels, such as Google, TikTok, and others, might be a serious challenge. It's crucial to determine how to create the best combination of these channels to achieve your goals. Your marketing mix (the percentage of advertising budgets invested in different channels) might include 50% on Google, 30% on Meta, 10% on TikTok, and so on. Each channel has its own optimization mechanisms, and it's important to identify which of them is best suited for your company. Some optimization engines work better on specific channels based on their audience and unique integrations. For example, gaming companies value integrations with games and formats not available in standard advertising networks. Within each channel, you conduct A/B tests to find the most effective creative solutions – banners, videos, and targeting settings. Suitable assets will help you address your objectives most efficiently. The second question pertains to cross-channel strategies. This involves determining where to direct your audience based on their behavior. For example, if you understand that some users start the checkout process in a mobile app while commuting to work and then complete it on the website, you can adapt your advertising to optimize the process for such users. This also involves personalized advertising at different times of the day and utilizing AI-powered tools to predict the effectiveness of different banners and ad settings. In the end, your task is to find the optimal combination of channels, optimize each channel, and create a cross-channel strategy based on an understanding of your audience's behavior. Predictive UA & Conventional Bidding Practices Typically, you gather a sufficient amount of historical data, usually over 5,000 unique users. Then, your raw data is converted into a numerical format, as predictive models work with numbers instead of text. The process looks like this: Data Preparation: The data you plan to use for model training must be transformed into a numerical format. Model Training: Historical user activity data is used to train the model. The model is trained to predict how much money new users can bring based on patterns in their activity. Model Evaluation: The model is evaluated based on its ability to make predictions. Model Deployment: After training, the model can be deployed in real-time, so you can predict the values of users currently interacting with your app. Real-time Data Collection: New user activity data is collected in real-time. Lemon AI fully automates these steps for you with its patented deep learning technology that boasts over 90% prediction accuracy. You only need to choose what you want to predict: this can either be a conventional performance marketing KPI (e.g., ROAS, LTV, retention, ARPU, and CAC) or any custom metric crucial to your business. Whether it's identifying users who spend 100 gems after completing 20 levels in your game or those who place a minimum of 3 orders worth 0 within the last 30 days on your e-commerce platform, our solution will help you identify the most important metrics based on raw data analysis and create a custom event to boost your app or website performance. All the rest – model training, feature engineering, data parsing, and conversion into actionable insights happen automatically and do not require you to get deep into the tech. No-code data transfer via Pull & Push API takes only 30 minutes, with deep learning models trained within 48 hours. The fast Track feature allows you to start generating first predictions within 15 seconds of a new user's app launch, even with SKAN limitations. Seamless integration with leading mobile management partners and analytics services further streamlines the process. In your ad manager, you can monitor in real time how your optimized campaigns perform and adjust them based on actual results and model predictions. Lemon AI's intuitive interface eliminates the need for dedicated managers or coding skills, so campaign optimization becomes as simple as pressing a few buttons, sparing you the tech intricacies. Our end-to-end analytics solution helps automate matching data across different data storages, whether it be Mobile Measurement Platforms (MMPs), CRMs, backend storages, etc. This allows businesses to seamlessly get actionable insights from the whole range of raw data they possess. Automating all the above-mentioned steps makes ad buying way more efficient. By directing your advertising efforts based on automated campaigns and detailed analytics, you can improve KPIs by 30-40% compared to traditional advertising methods. It actually works! Lemon AI enables companies to harness advanced deep learning technology in alignment with their goals, whether that means enhancing KPIs while maintaining costs or vice versa – reducing costs without compromising KPIs. In just six months, we've optimized a total ad spend of .2 million for more than 60 clients from industries such as e-commerce, banking, gaming, delivery, hospitality, and travel. Here are just two brief examples. Case 1: LTV growth by 49% in e-commerce Challenge: A top e-commerce platform in the MENA region, with 25 million installs and 650K+ monthly average users, struggled with low LTV, AOV, and retention rates despite a wide product range. The mobile app was leveraging predictive user acquisition and analytics tools to little effect. The aim was to drive sustainable growth in business metrics by implementing a comprehensive digital marketing strategy and optimizing Google Ads & Meta Ads channels to attract high-value users, encourage repeat purchases, and develop predictive personal dynamic offers. How we got there in 3 steps: We analyzed data to forecast buying habits and churn likelihood, as well as optimize user acquisition and retention strategies. We targeted users with the top 35% LTV within 60 days and those making 3+ purchases within 30 days post-installation. After 3 months, we reduced CAC by 17.9%, optimized banners, texts, and USPs. We implemented personalized product recommendations based on purchase history to enhance the shopping experience, boosting AOV by 59% over five months. Results: For Android: +35% Retention, +42% AOV, +49% LTV on Day 60 For iOS: +17% Retention, +33% AOV, +32% LTV on Day 60 Case 2: ROAS surged by 42% for a casual game Challenge: The client - a casual game with over 5M installs and 700K monthly average users - sought to optimize their advertising strategy in order to maximize revenue across MENA, Europe, and APAC regions while balancing user experience and engagement. The goal was to increase ROAS and Retention with in-app purchases using data from AppsFlyer. How we got there: In just eight days, the Lemon AI model was fully trained and integrated, with no code required. We made ML-based predictions for the Top 10%, 20%, and 30% of players by revenue. For players who reached ‘level 10' and spent a total of 200 ‘diamonds,' we created a tailored event that served as a proxy metric and enhanced efficiency. Results: +17% overall efficiency cf. client's internal benchmark For Android: +42% ROAS, +28% Ad Revenue For iOS: +27% ROAS, +16% Ad Revenue
How to Power up your Digital Marketing with Deep Learning...
“We're at the beginning of a golden age of AI and are solving problems that...
Source: Hacker Noon
Take A Tour! NIST Cybersecurity Framework 2.0: Small Business Quick Start Guide

The U.S. Small Business Administration is celebrating National Small Business Week from April 28 - May 4, 2024. This week recognizes and celebrates the small business community's significant contributions to the nation. Organizations across the country participate by hosting in-person and virtual events, recognizing small business leaders and change-makers, and highlighting resources that help the small business community more easily and efficiently start and scale their businesses. To add to the festivities, this NIST Cybersecurity Insights blog showcases the NIST Cybersecurity Framework 2.0
Take A Tour! NIST Cybersecurity Framework 2.0: Small...
The U.S. Small Business Administration is celebrating National Small Business Week...
Source: NIST
Honeypots 101: A Beginner’s Guide to Honeypots

Exploring Honeypots And The Art of Cybersecurity DeceptionPhoto by Hanna Balan on UnsplashIntroductionEver wanted a front-row seat to watch attackers at work? Bored of reading about attacker techniques and frameworks like MITRE? Would you like to gain firsthand insight into how real-world attacks unfold? Honeypots are a great way to get that experience. What started as a small experiment after accidentally leaving a Python web server running on a test machine has turned into a personal project to dive deeper into honeypots and share the experience with you.Honeypots offer a unique way to learn about cybersecurity attacks by attracting and studying real-world attackers. Setting up a honeypot allows you to observe and analyze threats in real-time, helping you gain practical experience and insight into how attackers operate. I'm exploring honeypots because I believe that to be effective in cybersecurity, you need to see the action up close, not just read about it.Throughout this article, we'll discuss what honeypots are, why they're useful, and how to set them up, along with some safety tips to keep in mind. Join me as I explore the world of honeypots and share what I learn.What Is a Honeypot?A honeypot is a system or software designed to simulate a real environment, attracting attackers while logging and analyzing their activities. It can be set up to look like a vulnerable website, a database, or any other service attackers might target. The purpose is to study attack techniques, gather threat intelligence, and improve cybersecurity defences.These honeypots are strategically placed in parts of your network where they are likely to attract malicious traffic, yet are isolated to ensure safety. Once in place, they act like regular systems with fake vulnerabilities, weak passwords, and open ports, enticing attackers to engage.Every interaction with the honeypot is logged, allowing you to gather valuable data on the tactics, techniques, and procedures used by attackers. This information can be analyzed to understand common attack patterns, emerging threats, and ways to improve cybersecurity defences. Honeypots also serve as an early warning system, alerting you to potential threats before they reach your core systems.Additionally, honeypots provide a safe environment for incident response training and developing defensive strategies without impacting real data or users. By studying attackers in this controlled setting, you gain practical experience and insights that can help strengthen your cybersecurity skills.Benefits of Using HoneypotsDeploying, running and working with honeypots offer cybersecurity professionals many benefits. I've listed three reasons I believe to be the most interesting to beginners or aspiring cybersecurity candidates below.Learning Attack Techniques: Honeypots give you firsthand experience with real-world attacks, helping you understand offensive security strategies. This is valuable for both, attackers and defenders.2. Enhancing Your Cybersecurity Portfolio: Working with honeypots can be a valuable addition to your resume, showcasing your hands-on skills in cybersecurity. This demonstrates your skills in working with Linux, deploying and configuring honeypots and of course, analyzing attacks and potential malicious payloads.3. Practical Experience: Honeypots offer an interactive way to learn and gain practical experience in a controlled setting, allowing you to safely experiment with different attack scenarios and observe how attackers respond.For experienced cybersecurity professionals, honeypots offer several other advantages. Let's explore some of the key reasons why they are commonly used.Threat Intelligence: Honeypots can serve as a source of valuable threat intelligence, providing insights into emerging attack patterns, new tools, and techniques used by hackers. This information can help cybersecurity teams stay ahead of potential threats.Early Detection: By deploying honeypots as part of a broader security strategy, you can detect attackers who have breached other defences. This early warning system can help you respond faster to incidents.Deception Tactics: Honeypots can be used as part of a deception strategy to mislead attackers, making it harder for them to locate valuable targets within your network. This can slow down their progress and give you more time to respond.Training and Education: Honeypots provide a safe environment for cybersecurity training. Security professionals can practice attack scenarios, analyze attack methods, and develop responses without risk to actual systems or data.Types of HoneypotsHoneypots come in different shapes, sizes, interaction levels, deployment options etc. We will be exploring those options in the following sections.1. Honeypot Type By Interaction LevelInteraction level refers to the degree of engagement and complexity a honeypot offers to attackers, ranging from low-interaction which has basic fake services like SSH or HTTP, to high-interaction with fully functional systems that mimic real-world environments. Let's classify them based on interaction level:Low-Interaction Honeypots: These honeypots simulate basic services like SSH or HTTP, providing limited interaction with attackers. They're easier to set up but offer less data.Medium-Interaction Honeypots: These honeypots simulate more complex services, allowing attackers to interact more deeply. They offer a good balance of information and complexity.High-Interaction Honeypots: These are full systems with a wide range of services. They provide the most detailed information but require more resources and careful management.2. Honeypot Types By Deployment OptionsHoneypots can be deployed in various ways, depending on your goals, resources, and security needs. Here are the common types of honeypots based on deployment options:Standalone Honeypots: These are dedicated systems or appliances set up exclusively as honeypots, separate from your main network and systems. They offer strong isolation and are ideal for high-interaction scenarios, where you want to contain any potential risks.Virtual Honeypots: Deployed on virtual machines or within containerized environments, these honeypots are flexible and scalable. They are a good option if you need to quickly spin up or tear down honeypots without much overhead.Cloud-Based Honeypots: These honeypots are hosted in the cloud, providing easy scalability and remote management. They are ideal for attracting attackers from the broader internet while keeping your on-premises infrastructure secure. They are also a good source of Threat Intel.Network-Integrated Honeypots: These honeypots are placed within a network to monitor specific segments, like internal traffic or external-facing services. They can serve as early warning systems for detecting unusual activity or intrusions in a controlled environment.Popular Honeypot ToolsIn this section, I am going to list some popular honeypot tools with brief descriptions and links to their websites.Disclaimer: The honeypot options listed below are free and open-source. This article is not intended as a review of commercial honeypot solutions.T-Pot: An All-in-one multi-honeypot platform that combines various honeypot technologies into one solution. Some of its features include visualization options using the Elastic Stack, animated live attack maps and lots of security tools to further improve the deception experience. This option requires at least 4GB RAM and 35GB of disk. The recommended minimum requirements by the creators are 8GB RAM and 128GB disk space if you are planning to store huge amounts of data and turn on all its features and services.OpenCanary: A lightweight multi-protocol network honeypot designed for easy deployment and low interaction. OpenCanary is daemon-based and can simulate various services like SSH, SMB, and FT. Its main attractiveness is the extremely low resource requirements; for example, it can be deployed easily on a Raspberry Pi, or a VM with minimal resources. With 25GB of disk space, you should have plenty of room for logs and system files.Cowrie: No list of honeypots is complete without mentioning Cowrie, an interactive SSH and Telnet honeypot that provides more detailed insights into attacker behaviour. However, it tends to be more resource-intensive than OpenCanary due to its interactive nature and additional logging. Excellent choice if you only want to run SSH-only honeypots.Honeyd: The OG of honeypots. Honeyd is a low-interaction honeypot that lets you create multiple virtual hosts on one machine. It's highly customizable and can simulate a range of services. Honeyd has been the go-to low-interaction honeypot for years, so much so that many modern honeypots draw inspiration from its features. Even though it hasn't seen major updates in a while, it remains highly effective and is a solid choice for a basic canary honeypot setup.The honeypots listed above are some of the most widely used and versatile open-source projects. If you need something more specialized, like simulating SCADA or IoT systems, there are plenty of other options out there. For a broader selection, take a look at the “Awesome Honeypots” GitHub page.Safety Tips and WarningsWhen setting up honeypots, safety should be your top priority. Whether you are setting honeypots up for learning or as an additional security layer for your network, extreme caution and careful planning are required to deploy and run honeypots safely without exposing your network to real compromise. Here are some safety and security tips you should consider:Do not deploy on sensitive networksKeep honeypots away from production systems or networks containing sensitive data. There are exceptions to this rule. In scenarios where you need decoys in production environments to detect internal attacks and lateral movements, you need to carefully plan the deployment so that a compromise of the honeypot itself does not aid the attacker in spreading malware or using it as a pivot into the network. This type of honeypot should NOT be exposed publicly.Ensure isolationUse virtual machines or separate physical networks to isolate honeypots from your main environment. This way, if attackers break into the honeypot, they can't jump over to your real systems. Keeping things isolated minimizes the risk and helps contain any potential threats.Limit to the functionalities you needKeep the honeypot simple and focused on detection, rather than providing complex services that might introduce vulnerabilities.Closely monitor the honeypot interactionsImplement robust monitoring and alerting systems to track all honeypot interactions, logs, and alerts. This ensures any suspicious activity is quickly detected and analyzed. That's the whole point of a honeypot, right? Don't let a potential attacker slip under your radar!Use unique passwordsDon't reuse passwords that are in use elsewhere, whether on your home network or at work. This is to prevent a compromise of the honeypot giving away the keys to your real kingdom!Keep an eye on resource consumptionIf you have deployed your honeypot in the cloud, keep an eye on the resource utilization of your honeypot to avoid running up your monthly bills!ConclusionHoneypots are an exciting and effective way to learn about cybersecurity threats and defences. By observing real-world attacks, you can gain invaluable insights into how attackers operate and how to counter them.We've explored different types of honeypots based on their interaction level and deployment options. From low-resource virtual machines to large-scale, network-integrated setups, there's a honeypot for every purpose.Just remember, safety comes first — avoid deploying honeypots on your production or home network if they're public-facing. It's all about learning, not risking your real systemsAs I continue my honeypot project, I look forward to sharing my experiences and insights with you.Stay tuned for more updates and feel free to follow along on this journey of exploring honeypots! 🍯.Now, Go and Play!CyberSecMaverickHoneypots 101: A Beginner's Guide to Honeypots was originally published in InfoSec Write-ups on Medium, where people are continuing the conversation by highlighting and responding to this story.
Honeypots 101: A Beginner’s Guide to Honeypots...
Exploring Honeypots And The Art of Cybersecurity DeceptionPhoto by Hanna Balan on UnsplashIntroductionEver...
Source: InfoSec Write-ups
Simple Wonders of RAG using Ollama, Langchain and ChromaDB

Dive with me into the details of how you can use RAG to produce interesting results for questions related to a specific domain without needing to fine-tune your own model. What is RAG? RAG or Retrieval Augmented Generation is a really complicated way of saying “Knowledge base + LLM.” It describes a system that adds extra data, in addition to what the user provided, before querying the LLM. Where did that additional data come from? It could be from a number of different sources like vector databases, search engines, other pre-trained LLMs, etc. You can read my article for some more context about RAG. How does it work in practice? 1. No RAG, aka Base Case Before we get to RAG, we need to discuss “Chains” — the raison d'être for Langchain's existence. From Langchain documentation, Chains refer to sequences of calls — whether to an LLM, a tool, or a data preprocessing step. You can see more details in the experiments section. A simple chain you can set up would look something like — chain = prompt | llm | output As you can see, this is very straightforward. You are passing a prompt to an LLM of choice and then using a parser to produce the output. You are using langchain's concept of “chains” to help sequence these elements, much like you would use pipes in Unix to chain together several system commands like ls | grep file.txt. 2. With RAG The majority of use cases that use RAG today do so by using some form of vector database to store the information that the LLM uses to enhance the answer to the prompt. You can read how vector stores (or vector databases) store information and why it's a better alternative than something like a traditional SQL or NoSQL store here. There are several flavors of vector databases ranging from commercial paid products like Pinecone to open-source alternatives like ChromaDB and FAISS. I typically use ChromaDB because it's easy to use and has a lot of support in the community. At a high level, this is how RAG works with vector stores — Take the data you want to provide as contextual information for your prompt and store them as vector embeddings in your vector store of choice. Preload this information so that it's available to any prompt that needs to use it. At the time of prompt processing, retrieve the relevant context from the vector store — this time by embedding your query and then running a vector search against your store. Pass that along with your prompt to the LLM so that the LLM can provide an appropriate response. 💲 Profit 💲 In practice, a RAG chain would look something like this — docs_chain = create_stuff_documents_chain(llm, prompt) retriever = vector_store.as_retriever() retrieval_chain = create_retrieval_chain(retriever, docs_chain) If you were to simplify the details of all these langchain functions like create_stuff_documents_chain and create_retrieval_chain (you can read up on these in Langchain's official documentation) really, what it boils down to is something like — context_data = vector_store chain = context_data | llm | prompt which at a high level isn't all that different from the base case shown above. The main difference is the inclusion of the contextual data that is provided with your prompt. And that, my friends, is RAG. However, like all modern software, things can't be THAT simple. So there is a lot of syntactic sugar to make all of these things work, which looks like — docs_chain = create_stuff_documents_chain(llm, prompt) retriever = vector_store.as_retriever() retrieval_chain = create_retrieval_chain(retriever, docs_chain) As you can see in the diagram above there are many things happening to build an actual RAG-based system. However, if you focus on the “Retrieval chain,” you will see that it is composed of 2 main components — the simple chain on the bottom and the construction of the vector data on the top Bob's your uncle. Running Experiments To demonstrate the effectiveness of RAG, I would like to know the answer to the question — How can langsmith help with testing? For those who are unaware, Langsmith is Langchain's product offering, which provides tooling to help develop, test, deploy, and monitor LLM applications. Since unpaid versions of LLMs (as of 4/24) still have the limitation of not being connected to the internet and are trained on data from before 2021, Langsmith is not a concept known to LLMs. The usage of RAG here would be to see if providing context about Langsmith helps the LLM provide a better version of the answer to the question above. 1. Without RAG from langchain_community.llms import Ollama from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser # Simple chain invocation ## LLM + Prompt llm = Ollama(model="mistral") output = StrOutputParser() prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a skilled technical writer.", ), ("human", "{user_input}"), ] ) chain = prompt | llm | output ## Winner winner chicken dinner response = chain.invoke({"user_input": "how can langsmith help with testing?"}) print(":::ROUND 1:::") print(response) Output :::ROUND 1::: SIMPLE RETRIEVAL Langsmith, being a text-based AI model, doesn't directly interact with software or perform tests in the traditional sense. However, it can assist with various aspects of testing through its strong language processing abilities. Here are some ways Langsmith can contribute to testing: 1. Writing test cases and test plans: Langsmith can help write clear, concise, and comprehensive test cases and test plans based on user stories or functional specifications. It can also suggest possible edge cases and boundary conditions for testing. 2. Generating test data: Langsmith can create realistic test data for different types of applications. This can be especially useful for large datasets or complex scenarios where generating data manually would be time-consuming and error-prone. 3. Creating test scripts: Langsmith can write test scripts in popular automation frameworks such as Selenium, TestNG, JMeter, etc., based on the test cases and expected outcomes. 4. Providing test reports: Langsmith can help draft clear and concise test reports that summarize the results of different testing activities. It can also generate statistics and metrics from test data to help identify trends and patterns in software performance. 5. Supporting bug tracking systems: Langsmith can write instructions for how to reproduce bugs and suggest potential fixes based on symptom analysis and past issue resolutions. 6. Automating regression tests: While it doesn't directly execute automated tests, Langsmith can write test scripts or provide instructions on how to automate existing manual tests using tools like Selenium, TestComplete, etc. 7. Improving testing documentation: Langsmith can help maintain and update testing documentation, ensuring that all relevant information is kept up-to-date and easily accessible to team members. ❌ As you can see, there are no references to any testing benefits of Langsmith (“Langsmith, being a text-based AI model, doesn't directly interact with software or perform tests in the traditional sense.”). All the verbiage is super vague, and the LLM is hallucinating to come up with insipid cases in an effort to try to answer the question. (“Langsmith can write test scripts in popular automation frameworks such as Selenium, TestNG, JMeter, etc., based on the test cases and expected outcomes”). 2. With RAG The extra context is coming from a webpage that we will be loading into our vector store. from langchain_community.llms import Ollama from langchain_community.document_loaders import WebBaseLoader from langchain_community.embeddings import OllamaEmbeddings from langchain_community.vectorstores import FAISS from langchain_core.prompts import ChatPromptTemplate from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains import create_retrieval_chain # Invoke chain with RAG context llm = Ollama(model="mistral") ## Load page content loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide") docs = loader.load() ## Vector store things embeddings = OllamaEmbeddings(model="nomic-embed-text") text_splitter = RecursiveCharacterTextSplitter() split_documents = text_splitter.split_documents(docs) vector_store = FAISS.from_documents(split_documents, embeddings) ## Prompt construction prompt = ChatPromptTemplate.from_template( """ Answer the following question only based on the given context <context> {context} </context> Question: {input} """ ) ## Retrieve context from vector store docs_chain = create_stuff_documents_chain(llm, prompt) retriever = vector_store.as_retriever() retrieval_chain = create_retrieval_chain(retriever, docs_chain) ## Winner winner chicken dinner response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"}) print(":::ROUND 2:::") print(response["answer"]) Output :::ROUND 2::: RAG RETRIEVAL Langsmith is a platform that helps developers test and monitor their Large Language Model (LLM) applications in various stages of development, including prototyping, beta testing, and production. It provides several workflows to support effective testing: 1. Tracing: Langsmith logs application traces, allowing users to debug issues by examining the data step-by-step. This can help identify unexpected end results, infinite agent loops, slower than expected execution, or higher token usage. Traces in Langsmith are rendered with clear visibility and debugging information at each step of an LLM sequence, making it easier to diagnose and root-cause issues. 2. Initial Test Set: Langsmith supports creating datasets (collections of inputs and reference outputs) and running tests on LLM applications using these test cases. Users can easily upload, create on the fly, or export test cases from application traces. This allows developers to adopt a more test-driven approach and compare test results across different model configurations. 3. Comparison View: Langsmith's comparison view enables users to track and diagnose regressions in test scores across multiple revisions of their applications. Changes in the prompt, retrieval strategy, or model choice can have significant implications on the responses produced by the application, so being able to compare results for different configurations side-by-side is essential. 4. Monitoring and A/B Testing: Langsmith provides monitoring charts to track key metrics over time and drill down into specific data points to get trace tables for that time period. This is helpful for debugging production issues and A/B testing changes in prompt, model, or retrieval strategy. 5. Production: Once the application hits production, Langsmith's high-level overview of application performance with respect to latency, cost, and feedback scores ensures it continues delivering desirable results at scale. ✅ As you can see, there are very specific references to the testing capabilities of Langsmith, which we were able to extract due to the supplemental knowledge provided using the PDF. We were able to augment the capabilities of the standard LLM with the specific domain knowledge required to answer this question. So what now? This is just the tip of the iceberg with RAG. There is a world of optimizations and enhancements you can make to see the full power of RAG applied in practice. Hopefully, this is a good launchpad for you to try out the bigger and better things yourself! To get access to the complete code, you can go here. Thanks for reading! ⭐ If you like this type of content, be sure to follow me or subscribe to https://a1engineering.substack.com/subscribe! ⭐
Simple Wonders of RAG using Ollama, Langchain and...
Dive with me into the details of how you can use RAG to produce interesting results...
Source: Hacker Noon

No Dev Team? No Problem: Writing Malware and Anti-Malware...
Source: InfoSec Write-ups
UK to Take Steps in Helping Protect Consumers Against Cyber Threats from Smart Devices
![]()
The UK has taken a pioneering step by introducing new laws aimed at safeguarding consumers against hacking and cyber-attacks while using internet-connected smart devices such as baby monitors, televisions, and speakers. Under these new laws, manufacturers are required to adhere to basic security standards, effectively prohibiting the use of weak, easily guessable default passwords such […] The post UK to Take Steps in Helping Protect Consumers Against Cyber Threats from Smart Devices first appeared on IT Security Guru. The post UK to Take Steps in Helping Protect Consumers Against Cyber Threats from Smart Devices appeared first on IT Security Guru.
UK to Take Steps in Helping Protect Consumers Against...
The UK has taken a pioneering step by introducing new laws aimed at safeguarding...
Source: IT Security Guru