Search results for Rancher Modules
Case of Malware Distribution Linking to Illegal Gambling Website Targeting Korean Web Server

AhnLab SEcurity intelligence Center (ASEC) has discovered evidence of a malware strain being distributed to web servers in South Korea, leading users to an illegal gambling site. After initially infiltrating a poorly managed Windows Internet Information Services (IIS) web server in Korea, the threat actor installed the Meterpreter backdoor, a port forwarding tool, and an IIS module malware tool. They then used ProcDump to exfiltrate account credentials from the server. IIS modules support expansion features of web servers such as... The post Case of Malware Distribution Linking to Illegal Gambling Website Targeting Korean Web Server appeared first on ASEC BLOG.
Case of Malware Distribution Linking to Illegal Gambling...
AhnLab SEcurity intelligence Center (ASEC) has discovered evidence of a malware...
Source: AhnLab
Effortless Assisted Injection in Multi-Module Android Projects: Introducing Anvil Utils
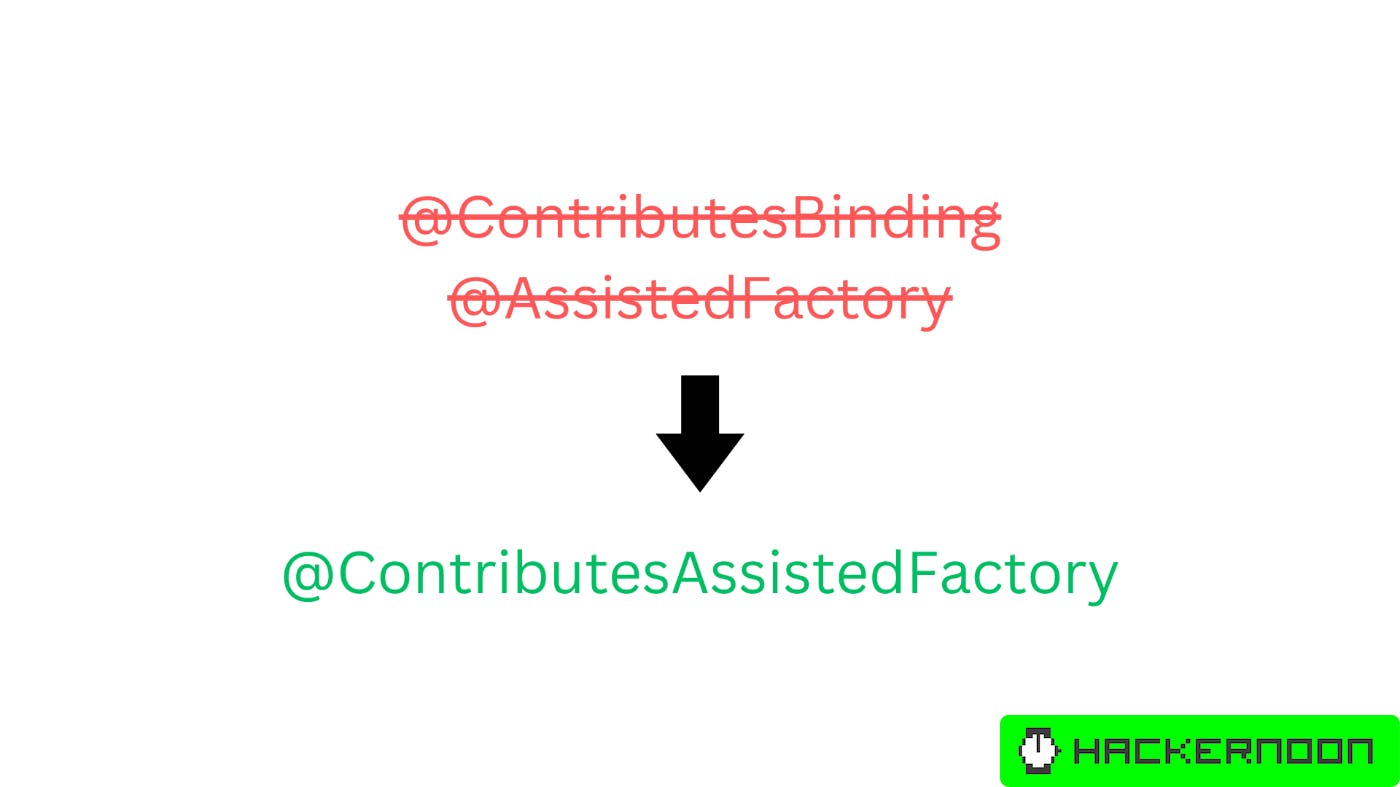
Anvil is a Kotlin compiler plugin which helps to drastically reduce the boilerplate needed to use Dagger 2 in your application. Also, if properly configured, it can improve build times in your application by removing the requirement to run Dagger 2 annotation processor in your feature modules.
Android Projects Anvil Utils Assisted Injection Introducing Anvil Kotlin compiler
Effortless Assisted Injection in Multi-Module Android...
Anvil is a Kotlin compiler plugin which helps to drastically reduce the boilerplate...
Source: Hacker Noon
Kaisen Linux | The distribution for professional IT

Kaisen Linux is a distribution dedicated for IT professional based on Debian GNU/Linux. Large tools are integrated for diagnostics, rescue system and networks, lab creation and many more!
Kaisen Linux | The distribution for professional IT...
Kaisen Linux is a distribution dedicated for IT professional based on Debian GNU/Linux....
HijackLoader Using Weaponized PNG Files To Deliver Multiple Malware

HijackLoader, a modular malware loader observed in 2023, is evolving with new evasion techniques, as it is a variant using a PNG image to deliver next-stage malware like Amadey and Racoon Stealer. The variant includes new modules (modCreateProcess, modUAC) for process creation, UAC bypass, and anti-hooking (Heaven’s Gate). It also uses dynamic API resolution and […] The post HijackLoader Using Weaponized PNG Files To Deliver Multiple Malware appeared first on Cyber Security News.
HijackLoader Using Weaponized PNG Files To Deliver...
HijackLoader, a modular malware loader observed in 2023, is evolving with new evasion...
Source: Latest Hacker and Security News
Join Morph’s Revolution With The Launch Of Holesky Testnet

Morph, an Ethereum layer 2 leading a Consumer Blockchain revolution, has announced the launch of its latest advancement, its Holesky Testnet. This new development comes on the heels of their successful Morph Sepolia Testnet and introduces a highly anticipated platform that showcases significant improvements in blockchain infrastructure and application. Already known for its commitment to consumer-centric solutions, Morph stands as a unique player in the space by focusing on real-world utility over the often speculative nature of many blockchain applications. Unlike traditional platforms that prioritize DeFi and trading, Morph aims to provide services that people can use daily, making blockchain technology an integral part of everyday life. The launch of the Holesky Testnet with its enhanced capabilities is a crucial step towards realizing this vision, bridging the gap between sophisticated technology and practical, everyday applications. Key Features and Innovations of the Morph Holesky Testnet: Enhanced Performance and Infrastructure The Holesky Testnet operates using Ethereum Holesky as Layer 1, elevating standards for performance and aligning closely with the infrastructure of the anticipated mainnet. This transition promises users a seamless and advanced preview of what to expect with the full launch. Advanced Features EIP-4844 Optimistic zkEVM Integration: This integration significantly reduces transaction costs, making blockchain operations more efficient. Revamped Bridge Mechanism: The updated bridge mechanism now allows for withdrawals to be finalized in just one transaction, enhancing the user experience. Robust Decentralized Sequencer Network: With fully decentralized modules and an increased number of sequencers, the network's backbone is stronger than ever, ensuring unparalleled reliability and security. Economic System Innovations The testnet introduces a novel economic model centered around a decentralized sequencer network, positioning Morph to set new market trends and standards. Impact on the Morph Community For testnet users, prior contributions to the Sepolia testnet are well recorded. Users are now encouraged to transition to the Holesky testnet to benefit from lower fees and superior functionality. For developers, Morph recommends migrating contracts from the Sepolia to the Holesky testnet. Detailed guidance on this process can be found here. The explorer is accessible for tracking deployments and interactions at Holesky Testnet Explorer. Engaging with Morph's New Testnet: Developers new to Morph's platform can quickly get up to speed through the comprehensive documentation available. For those already familiar with the Sepolia testnet, the core steps to engage with Holesky remain consistent. Start by deep diving into Morph's technology on the About Morph Page, then understand the inner workings of Morph's infrastructure, and start the development journey with a quickstart guide. For more, review comprehensive Developer Documentation to build innovative blockchain applications. Morph invites the global tech community to join in this revolutionary phase. This new testnet is a significant leap towards realizing a consumer-centric blockchain ecosystem that promises to redefine interaction with technology. About Morph Morph is a fully permissionless EVM L2 that uses a combination of optimistic and zero knowledge rollup technology to enable limitless possibilities in finance, gaming, social media, and entertainment. Morph is the first Layer 2 on Ethereum to launch with a decentralized sequencer, aligning it with several core principles of web3 — decentralization, censorship resistance, and security. The blockchain was built with mainstream audiences like gamers and social media users in mind, making it a user-friendly option for developers who require a chain to build these types of apps on. Website | Twitter |Discord | Telegram |Medium|Linkedin :::tip This story was distributed as a release by Btcwire under HackerNoon's Business Blogging Program. Learn more about the program here. :::
Join Morph’s Revolution With The Launch Of Holesky...
Morph, an Ethereum layer 2 leading a Consumer Blockchain revolution, has announced...
Source: Hacker Noon
AutofacServiceProviderFactory in ASP.NET Core - Part 1

We have plenty of awesome options for dependency injection when working in ASP.NET Core applications. For the most part, if you're not building anything super complicated concerning your types or your software architecture, you can get by with the built-in IServiceCollection. However, we can use AutofacServiceProviderFactory in ASP.NET Core to make Autofac our dependency container of choice in our app! In this article, I highlight how to use AutofacServiceProviderFactory in your ASP.NET Core application along with what you can and cannot do with it. Having many options for dependency injection means that we have many pros and cons to analyze! This will be part of a series where I explore dependency resolution with Autofac inside ASP.NET Core. I'll be sure to include the series below as the issues are published: Part 1: AutofacServiceProviderFactory in ASP.NET Core - Problems With Dependency Injection Part 2: Autofac ContainerBuilder In ASP.NET Core – What You Need To Know Part 3: Autofac ComponentRegistryBuilder in ASP.NET Core - How To Register Dependencies At the end of this series, you'll be able to more confidently explore plugin architectures inside of ASP.NET Core and Blazor, which will provide even more content for you to explore. Dependency Injection: A Primer What is Dependency Injection Dependency Injection (DI) is a design pattern used in programming to make software systems easier to develop, test, and maintain. In C#, like in many other programming languages, dependency injection helps to decouple the components of your applications. Ideally, this leads to developing software that is more flexible and extensible. Dependency Injection is about removing the hard-coded dependencies and making it possible to change them, either at runtime or compile time. This can be useful for many reasons, such as allowing a program to use different databases or testing components by replacing them with mock objects. Consider a code example where we create an instance of a car with an engine: public sealed class Car { private readonly IEngine _engine; public Car() { // The Car class directly depends on the GasEngine class. _engine = new GasEngine(); } } We can instead “inject” the dependency via the constructor: public sealed class Car { private readonly IEngine _engine; // The engine is injected into the car via the constructor // so now there is no direct dependency on the Engine class, // but there is a dependency on the IEngine interface // which has nothing to do with the implementation public Car(IEngine engine) { _engine = engine; } } We can even use the idea of a “Dependency Container” that helps make this process seem a bit more magical by not requiring us to explicitly create instances of objects by passing in dependencies. Instead, the container allows us to resolve these dependencies. More on that in the next section! What is Autofac? Autofac is a popular inversion of control (IoC) container for .NET. It manages the dependencies between classes by injecting instances where needed, thereby facilitating a more modular and testable codebase. Autofac is used extensively in applications to implement the dependency injection pattern, allowing us to write cleaner, more maintainable code for the reasons I explained in the previous section. There are other IoC containers to help us manage and resolve dependencies in our applications, including the built-in IServiceCollection, but Autofac is the one that I am most comfortable using. As .NET has evolved IServiceCollection has become more feature-rich, and with the gap in features between the two closing, Autofac is still one that I like using in my development. What is the AutofacServiceProviderFactory in ASP.NET Core? The AutofacServiceProviderFactory is a specific component in the Autofac library designed to integrate Autofac with the built-in dependency injection (DI) system in ASP.NET Core. Essentially, it acts as a bridge, allowing you to use Autofac as the DI container instead of the default one provided by Microsoft. Exploring A Sample ASP.NET Core Application I wanted to make sure we had a common application to refer to when I get into more of the technical details of what we do and do not get with AutofacServiceProviderFactory. The following code is the sample weather app we get from Visual Studio when creating a new ASP.NET Core web API, but I've modified it slightly to showcase some of the behavior we get with AutofacServiceProviderFactory: using Autofac; using Autofac.Extensions.DependencyInjection; using Microsoft.AspNetCore.Mvc; var builder = WebApplication.CreateBuilder(args); builder.Host.UseServiceProviderFactory(new AutofacServiceProviderFactory(containerBuilder => { containerBuilder .RegisterInstance(builder) .SingleInstance(); containerBuilder .Register(ctx => ctx.Resolve<WebApplicationBuilder>().Configuration) .SingleInstance(); // FIXME: we can't do this because the WebApplicationBuilder // the WebApplicationBuilder is responsible for building the // WebApplication, so we can't do that manually just to add // it into the container //containerBuilder // .Register(ctx => // { // var app = ctx.Resolve<WebApplicationBuilder>().Build(); // app.UseHttpsRedirection(); // return app; // }) // .SingleInstance(); containerBuilder.RegisterType<DependencyA>().SingleInstance(); containerBuilder.RegisterType<DependencyB>().SingleInstance(); containerBuilder.RegisterType<DependencyC>().SingleInstance(); //containerBuilder // .RegisterBuildCallback(ctx => // { // // FIXME: this was never registered // var app = ctx.Resolve<WebApplication>(); // var summaries = new[] // { // "Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching" // }; // app.MapGet( // "/weatherforecast", // ( // [FromServices] DependencyA dependencyA // this will work // , [FromServices] DependencyB dependencyB // FIXME: this will fail!! // , [FromServices] DependencyC dependencyC // this will work // ) => // { // var forecast = Enumerable.Range(1, 5).Select(index => // new WeatherForecast // ( // DateOnly.FromDateTime(DateTime.Now.AddDays(index)), // Random.Shared.Next(-20, 55), // summaries[Random.Shared.Next(summaries.Length)] // )) // .ToArray(); // return forecast; // }); // }); })); // FIXME: we can't get the WebApplication into the // Autofac container, because it's already been built. // this means if we have anything that wants to take a // dependency on the WebApplication instance itself, we // can't resolve it from the container. var app = builder.Build(); app.UseHttpsRedirection(); var summaries = new[] { "Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching" }; app.MapGet( "/weatherforecast", ( [FromServices] DependencyA dependencyA // this will work , [FromServices] DependencyB dependencyB // FIXME: this will fail!! , [FromServices] DependencyC dependencyC // this will work ) => { var forecast = Enumerable.Range(1, 5).Select(index => new WeatherForecast ( DateOnly.FromDateTime(DateTime.Now.AddDays(index)), Random.Shared.Next(-20, 55), summaries[Random.Shared.Next(summaries.Length)] )) .ToArray(); return forecast; }); app.Run(); internal record WeatherForecast(DateOnly Date, int TemperatureC, string? Summary) { public int TemperatureF => 32 + (int)(TemperatureC / 0.5556); } internal sealed class DependencyA( WebApplicationBuilder _webApplicationBuilder); internal sealed class DependencyB( Lazy<WebApplication> _webApplication); internal sealed class DependencyC( IConfiguration _configuration); You should note that I've modified the weather API itself to take in 3 dependencies that we want to resolve from the service list. [FromService] is, in fact, not required here, but it makes the error messages clearer if you were to run this and want to understand where and why it fails. But wait… why does it fail?! Keep on readin' and follow along with this video on Autofac to find out more: https://youtu.be/pjvtZGJTqHg?embedable=true What Can We Get With AutofacServiceProviderFactory in ASP.NET Core? Let's start off with what we get from this setup because I do think that this is the typical path. To be clear, there's nothing “wrong” with this approach, but you need to understand where dependencies are registered and resolved, and, therefore what works with your container: We have access to the WebApplicationBuilder on the Autofac ContainerBuilder instance. This allows us to have services depending on the app builder instance, which means we can have modules and/or plugins that want to setup information on the app builder or otherwise read state from the app builder. With that said, we have access to the IConfiguration instance from the WebApplicationBuilder because it's exposed on the web app builder itself. We get the ability to resolve dependencies from the container that are defined directly on our minimal APIs! In the example I shared above, the dependency classes A through C are all types that can be resolved from the container automatically on the minimal API. There's a catch for one of these, which we'll cover, but the point is that our minimal API can see their registrations. In general, this is probably “good enough” for most situations if you just want to use Autofac for your ASP.NET Core application. However, this is limiting to the style of development that I like to do. What's Missing With AutofacServiceProviderFactory in ASP.NET Core? Now that we've seen the goodness that we get, let's discuss where there are some drawbacks. They're essentially already highlighted in the code with FIXME comments, but it's worth elaborating on them in more detail here. Again, this is not to suggest this is the “wrong” way to do it, just that you have some considerations to make: The WebApplication instance is not something that we can resolve from the container. That is, if you ever want to have classes automatically resolve from the dependency container, they cannot take a dependency on WebApplication. This is because this instance is never registered onto the container and, therefore, cannot be automatically injected for us. We can't overcome this behavior by calling the Build() method manually on the WebApplicationBuilder inside of an Autofac registration. This is because the chain of registrations executes once we call Build() on the web application builder OUTSIDE of the container, which then handles the rest of the application being built. Said another way, this creates a bit of a circular dependency on the responsibilities that need to be handled. Because we cannot resolve the WebApplication instance from the dependency container, we cannot create plugins that add their own routes to the application using the minimal API route registration syntax. If this is indeed possible to do, it would have to be using a different API and instance of a different type since the WebApplication instance is not accessible to us via the container. Based on the above points, we cannot have dependencies on the routes like DependencyB in the example above. This is because this type has a dependency on WebApplication and the container simply does not know about it. In future articles, you'll see examples of this pattern coming up again, so it's worth mentioning in this article for reference. Many of these are not a concern for folks building typical applications. However, as someone who builds mostly plugin architecture applications, this is very limiting for me! Wrapping Up AutofacServiceProviderFactory in ASP.NET Core In this article, I provided a brief overview of dependency injection and Autofac within ASP.NET Core. The primary takeaway was looking at what you do and do not get when using AutofacServiceProviderFactory in ASP.NET Core. While the limitations of this are minimized for the average application, this does not work well for a plugin architecture that wants to extend the API routes via plugins. If you found this useful and you're looking for more learning opportunities, consider subscribing to my free weekly software engineering newsletter and check out my free videos on YouTube!
AutofacServiceProviderFactory in ASP.NET Core - Part...
We have plenty of awesome options for dependency injection when working in ASP.NET...
Source: Hacker Noon
Implementing LICMA: Python and Java Analysis Components for Crypto Misuse Detection

LICMA implements crypto analysis for Python and Java, covering key crypto modules and adhering to JCA rules. Python module selection is based on popularity and task-solving capabilities, with an emphasis on API design and usability. LICMA's implementation details are available on GitHub for exploration.
Implementing LICMA: Python and Java Analysis Components...
LICMA implements crypto analysis for Python and Java, covering key crypto modules...
Source: Hacker Noon
Debian LTS: DLA-3805-1: qtbase-opensource-src Security Advisory Updates

Several issues have been found in qtbase-opensource-src, a collection of several Qt modules/libraries. The issues are related to buffer overflows, infinite loops or application
Debian LTS: DLA-3805-1: qtbase-opensource-src Security...
Several issues have been found in qtbase-opensource-src, a collection of several...
Source: LinuxSecurity.com
Simple Wonders of RAG using Ollama, Langchain and ChromaDB

Dive with me into the details of how you can use RAG to produce interesting results for questions related to a specific domain without needing to fine-tune your own model. What is RAG? RAG or Retrieval Augmented Generation is a really complicated way of saying “Knowledge base + LLM.” It describes a system that adds extra data, in addition to what the user provided, before querying the LLM. Where did that additional data come from? It could be from a number of different sources like vector databases, search engines, other pre-trained LLMs, etc. You can read my article for some more context about RAG. How does it work in practice? 1. No RAG, aka Base Case Before we get to RAG, we need to discuss “Chains” — the raison d'être for Langchain's existence. From Langchain documentation, Chains refer to sequences of calls — whether to an LLM, a tool, or a data preprocessing step. You can see more details in the experiments section. A simple chain you can set up would look something like — chain = prompt | llm | output As you can see, this is very straightforward. You are passing a prompt to an LLM of choice and then using a parser to produce the output. You are using langchain's concept of “chains” to help sequence these elements, much like you would use pipes in Unix to chain together several system commands like ls | grep file.txt. 2. With RAG The majority of use cases that use RAG today do so by using some form of vector database to store the information that the LLM uses to enhance the answer to the prompt. You can read how vector stores (or vector databases) store information and why it's a better alternative than something like a traditional SQL or NoSQL store here. There are several flavors of vector databases ranging from commercial paid products like Pinecone to open-source alternatives like ChromaDB and FAISS. I typically use ChromaDB because it's easy to use and has a lot of support in the community. At a high level, this is how RAG works with vector stores — Take the data you want to provide as contextual information for your prompt and store them as vector embeddings in your vector store of choice. Preload this information so that it's available to any prompt that needs to use it. At the time of prompt processing, retrieve the relevant context from the vector store — this time by embedding your query and then running a vector search against your store. Pass that along with your prompt to the LLM so that the LLM can provide an appropriate response. 💲 Profit 💲 In practice, a RAG chain would look something like this — docs_chain = create_stuff_documents_chain(llm, prompt) retriever = vector_store.as_retriever() retrieval_chain = create_retrieval_chain(retriever, docs_chain) If you were to simplify the details of all these langchain functions like create_stuff_documents_chain and create_retrieval_chain (you can read up on these in Langchain's official documentation) really, what it boils down to is something like — context_data = vector_store chain = context_data | llm | prompt which at a high level isn't all that different from the base case shown above. The main difference is the inclusion of the contextual data that is provided with your prompt. And that, my friends, is RAG. However, like all modern software, things can't be THAT simple. So there is a lot of syntactic sugar to make all of these things work, which looks like — docs_chain = create_stuff_documents_chain(llm, prompt) retriever = vector_store.as_retriever() retrieval_chain = create_retrieval_chain(retriever, docs_chain) As you can see in the diagram above there are many things happening to build an actual RAG-based system. However, if you focus on the “Retrieval chain,” you will see that it is composed of 2 main components — the simple chain on the bottom and the construction of the vector data on the top Bob's your uncle. Running Experiments To demonstrate the effectiveness of RAG, I would like to know the answer to the question — How can langsmith help with testing? For those who are unaware, Langsmith is Langchain's product offering, which provides tooling to help develop, test, deploy, and monitor LLM applications. Since unpaid versions of LLMs (as of 4/24) still have the limitation of not being connected to the internet and are trained on data from before 2021, Langsmith is not a concept known to LLMs. The usage of RAG here would be to see if providing context about Langsmith helps the LLM provide a better version of the answer to the question above. 1. Without RAG from langchain_community.llms import Ollama from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser # Simple chain invocation ## LLM + Prompt llm = Ollama(model="mistral") output = StrOutputParser() prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a skilled technical writer.", ), ("human", "{user_input}"), ] ) chain = prompt | llm | output ## Winner winner chicken dinner response = chain.invoke({"user_input": "how can langsmith help with testing?"}) print(":::ROUND 1:::") print(response) Output :::ROUND 1::: SIMPLE RETRIEVAL Langsmith, being a text-based AI model, doesn't directly interact with software or perform tests in the traditional sense. However, it can assist with various aspects of testing through its strong language processing abilities. Here are some ways Langsmith can contribute to testing: 1. Writing test cases and test plans: Langsmith can help write clear, concise, and comprehensive test cases and test plans based on user stories or functional specifications. It can also suggest possible edge cases and boundary conditions for testing. 2. Generating test data: Langsmith can create realistic test data for different types of applications. This can be especially useful for large datasets or complex scenarios where generating data manually would be time-consuming and error-prone. 3. Creating test scripts: Langsmith can write test scripts in popular automation frameworks such as Selenium, TestNG, JMeter, etc., based on the test cases and expected outcomes. 4. Providing test reports: Langsmith can help draft clear and concise test reports that summarize the results of different testing activities. It can also generate statistics and metrics from test data to help identify trends and patterns in software performance. 5. Supporting bug tracking systems: Langsmith can write instructions for how to reproduce bugs and suggest potential fixes based on symptom analysis and past issue resolutions. 6. Automating regression tests: While it doesn't directly execute automated tests, Langsmith can write test scripts or provide instructions on how to automate existing manual tests using tools like Selenium, TestComplete, etc. 7. Improving testing documentation: Langsmith can help maintain and update testing documentation, ensuring that all relevant information is kept up-to-date and easily accessible to team members. ❌ As you can see, there are no references to any testing benefits of Langsmith (“Langsmith, being a text-based AI model, doesn't directly interact with software or perform tests in the traditional sense.”). All the verbiage is super vague, and the LLM is hallucinating to come up with insipid cases in an effort to try to answer the question. (“Langsmith can write test scripts in popular automation frameworks such as Selenium, TestNG, JMeter, etc., based on the test cases and expected outcomes”). 2. With RAG The extra context is coming from a webpage that we will be loading into our vector store. from langchain_community.llms import Ollama from langchain_community.document_loaders import WebBaseLoader from langchain_community.embeddings import OllamaEmbeddings from langchain_community.vectorstores import FAISS from langchain_core.prompts import ChatPromptTemplate from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains import create_retrieval_chain # Invoke chain with RAG context llm = Ollama(model="mistral") ## Load page content loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide") docs = loader.load() ## Vector store things embeddings = OllamaEmbeddings(model="nomic-embed-text") text_splitter = RecursiveCharacterTextSplitter() split_documents = text_splitter.split_documents(docs) vector_store = FAISS.from_documents(split_documents, embeddings) ## Prompt construction prompt = ChatPromptTemplate.from_template( """ Answer the following question only based on the given context <context> {context} </context> Question: {input} """ ) ## Retrieve context from vector store docs_chain = create_stuff_documents_chain(llm, prompt) retriever = vector_store.as_retriever() retrieval_chain = create_retrieval_chain(retriever, docs_chain) ## Winner winner chicken dinner response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"}) print(":::ROUND 2:::") print(response["answer"]) Output :::ROUND 2::: RAG RETRIEVAL Langsmith is a platform that helps developers test and monitor their Large Language Model (LLM) applications in various stages of development, including prototyping, beta testing, and production. It provides several workflows to support effective testing: 1. Tracing: Langsmith logs application traces, allowing users to debug issues by examining the data step-by-step. This can help identify unexpected end results, infinite agent loops, slower than expected execution, or higher token usage. Traces in Langsmith are rendered with clear visibility and debugging information at each step of an LLM sequence, making it easier to diagnose and root-cause issues. 2. Initial Test Set: Langsmith supports creating datasets (collections of inputs and reference outputs) and running tests on LLM applications using these test cases. Users can easily upload, create on the fly, or export test cases from application traces. This allows developers to adopt a more test-driven approach and compare test results across different model configurations. 3. Comparison View: Langsmith's comparison view enables users to track and diagnose regressions in test scores across multiple revisions of their applications. Changes in the prompt, retrieval strategy, or model choice can have significant implications on the responses produced by the application, so being able to compare results for different configurations side-by-side is essential. 4. Monitoring and A/B Testing: Langsmith provides monitoring charts to track key metrics over time and drill down into specific data points to get trace tables for that time period. This is helpful for debugging production issues and A/B testing changes in prompt, model, or retrieval strategy. 5. Production: Once the application hits production, Langsmith's high-level overview of application performance with respect to latency, cost, and feedback scores ensures it continues delivering desirable results at scale. ✅ As you can see, there are very specific references to the testing capabilities of Langsmith, which we were able to extract due to the supplemental knowledge provided using the PDF. We were able to augment the capabilities of the standard LLM with the specific domain knowledge required to answer this question. So what now? This is just the tip of the iceberg with RAG. There is a world of optimizations and enhancements you can make to see the full power of RAG applied in practice. Hopefully, this is a good launchpad for you to try out the bigger and better things yourself! To get access to the complete code, you can go here. Thanks for reading! ⭐ If you like this type of content, be sure to follow me or subscribe to https://a1engineering.substack.com/subscribe! ⭐
Simple Wonders of RAG using Ollama, Langchain and...
Dive with me into the details of how you can use RAG to produce interesting results...
Source: Hacker Noon
ThievingFox - Remotely Retrieving Credentials From Password Managers And Windows Utilities

ThievingFox is a collection of post-exploitation tools to gather credentials from various password managers and windows utilities. Each module leverages a specific method of injecting into the target process, and then hooks internals functions to gather crendentials. The accompanying blog post can be found here Installation Linux Rustup must be installed, follow the instructions available here : https://rustup.rs/ The mingw-w64 package must be installed. On Debian, this can be done using : apt install mingw-w64 Both x86 and x86_64 windows targets must be installed for Rust: rustup target add x86_64-pc-windows-gnurustup target add i686-pc-windows-gnu Mono and Nuget must also be installed, instructions are available here : https://www.mono-project.com/download/stable/#download-lin After adding Mono repositories, Nuget can be installed using apt : apt install nuget Finally, python dependancies must be installed : pip install -r client/requirements.txt ThievingFox works with python >= 3.11. Windows Rustup must be installed, follow the instructions available here : https://rustup.rs/ Both x86 and x86_64 windows targets must be installed for Rust: rustup target add x86_64-pc-windows-msvcrustup target add i686-pc-windows-msvc .NET development environment must also be installed. From Visual Studio, navigate to Tools > Get Tools And Features > Install ".NET desktop development" Finally, python dependancies must be installed : pip install -r client/requirements.txt ThievingFox works with python >= 3.11 NOTE : On a Windows host, in order to use the KeePass module, msbuild must be available in the PATH. This can be achieved by running the client from within a Visual Studio Developper Powershell (Tools > Command Line > Developper Powershell) Targets All modules have been tested on the following Windows versions : Windows Version Windows Server 2022 Windows Server 2019 Windows Server 2016 Windows Server 2012R2 Windows 10 Windows 11 [!CAUTION] Modules have not been tested on other version, and are expected to not work. Application Injection Method KeePass.exe AppDomainManager Injection KeePassXC.exe DLL Proxying LogonUI.exe (Windows Login Screen) COM Hijacking consent.exe (Windows UAC Popup) COM Hijacking mstsc.exe (Windows default RDP client) COM Hijacking RDCMan.exe (Sysinternals' RDP client) COM Hijacking MobaXTerm.exe (3rd party RDP client) COM Hijacking Usage [!CAUTION] Although I tried to ensure that these tools do not impact the stability of the targeted applications, inline hooking and library injection are unsafe and this might result in a crash, or the application being unstable. If that were the case, using the cleanup module on the target should be enough to ensure that the next time the application is launched, no injection/hooking is performed. ThievingFox contains 3 main modules : poison, cleanup and collect. Poison For each application specified in the command line parameters, the poison module retrieves the original library that is going to be hijacked (for COM hijacking and DLL proxying), compiles a library that has matches the properties of the original DLL, uploads it to the server, and modify the registry if needed to perform COM hijacking. To speed up the process of compilation of all libraries, a cache is maintained in client/cache/. --mstsc, --rdcman, and --mobaxterm have a specific option, respectively --mstsc-poison-hkcr, --rdcman-poison-hkcr, and --mobaxterm-poison-hkcr. If one of these options is specified, the COM hijacking will replace the registry key in the HKCR hive, meaning all users will be impacted. By default, only all currently logged in users are impacted (all users that have a HKCU hive). --keepass and --keepassxc have specific options, --keepass-path, --keepass-share, and --keepassxc-path, --keepassxc-share, to specify where these applications are installed, if it's not the default installation path. This is not required for other applications, since COM hijacking is used. The KeePass modules requires the Visual C++ Redistributable to be installed on the target. Multiple applications can be specified at once, or, the --all flag can be used to target all applications. [!IMPORTANT] Remember to clean the cache if you ever change the --tempdir parameter, since the directory name is embedded inside native DLLs. $ python3 client/ThievingFox.py poison -husage: ThievingFox.py poison [-h] [-hashes HASHES] [-aesKey AESKEY] [-k] [-dc-ip DC_IP] [-no-pass] [--tempdir TEMPDIR] [--keepass] [--keepass-path KEEPASS_PATH] [--keepass-share KEEPASS_SHARE] [--keepassxc] [--keepassxc-path KEEPASSXC_PATH] [--keepassxc-share KEEPASSXC_SHARE] [--mstsc] [--mstsc-poison-hkcr] [--consent] [--logonui] [--rdcman] [--rdcman-poison-hkcr] [--mobaxterm] [--mobaxterm-poison-hkcr] [--all] targetpositional arguments: target Target machine or range [domain/]username[:password]@<IP or FQDN>[/CIDR]options: -h, --help show this help message and exit -hashes HASHES, --hashes HASHES LM:NT hash -aesKey AESKEY, --aesKey AESKEY AES key to use for Kerberos Authentication -k Use kerberos authentication. For LogonUI, mstsc and consent modules, an anonymous NTLM authentication is performed, to retrieve the OS version. -dc-ip DC_IP, --dc-ip DC_IP IP Address of the domain controller -no-pass, --no-pass Do not prompt for password --tempdir TEMPDIR The name of the temporary directory to use for DLLs and output (Default: ThievingFox) --keepass Try to poison KeePass.exe --keepass-path KEEPASS_PATH The path where KeePass is installed, without the share name (Default: /Program Files/KeePass Password Safe 2/) --keepass-share KEEPASS_SHARE The share on which KeePass is installed (Default: c$) --keepassxc Try to poison KeePassXC.exe --keepassxc-path KEEPASSXC_PATH The path where KeePassXC is installed, without the share name (Default: /Program Files/KeePassXC/) --ke epassxc-share KEEPASSXC_SHARE The share on which KeePassXC is installed (Default: c$) --mstsc Try to poison mstsc.exe --mstsc-poison-hkcr Instead of poisonning all currently logged in users' HKCU hives, poison the HKCR hive for mstsc, which will also work for user that are currently not logged in (Default: False) --consent Try to poison Consent.exe --logonui Try to poison LogonUI.exe --rdcman Try to poison RDCMan.exe --rdcman-poison-hkcr Instead of poisonning all currently logged in users' HKCU hives, poison the HKCR hive for RDCMan, which will also work for user that are currently not logged in (Default: False) --mobaxterm Try to poison MobaXTerm.exe --mobaxterm-poison-hkcr Instead of poisonning all currently logged in users' HKCU hives, poison the HKCR hive for MobaXTerm, which will also work for user that are currently not logged in (Default: False) --all Try to poison all applications Cleanup For each application specified in the command line parameters, the cleanup first removes poisonning artifacts that force the target application to load the hooking library. Then, it tries to delete the library that were uploaded to the remote host. For applications that support poisonning of both HKCU and HKCR hives, both are cleaned up regardless. Multiple applications can be specified at once, or, the --all flag can be used to cleanup all applications. It does not clean extracted credentials on the remote host. [!IMPORTANT] If the targeted application is in use while the cleanup module is ran, the DLL that are dropped on the target cannot be deleted. Nonetheless, the cleanup module will revert the configuration that enables the injection, which should ensure that the next time the application is launched, no injection is performed. Files that cannot be deleted by ThievingFox are logged. $ python3 client/ThievingFox.py cleanup -husage: ThievingFox.py cleanup [-h] [-hashes HASHES] [-aesKey AESKEY] [-k] [-dc-ip DC_IP] [-no-pass] [--tempdir TEMPDIR] [--keepass] [--keepass-share KEEPASS_SHARE] [--keepass-path KEEPASS_PATH] [--keepassxc] [--keepassxc-path KEEPASSXC_PATH] [--keepassxc-share KEEPASSXC_SHARE] [--mstsc] [--consent] [--logonui] [--rdcman] [--mobaxterm] [--all] targetpositional arguments: target Target machine or range [domain/]username[:password]@<IP or FQDN>[/CIDR]options: -h, --help show this help message and exit -hashes HASHES, --hashes HASHES LM:NT hash -aesKey AESKEY, --aesKey AESKEY AES key to use for Kerberos Authentication -k Use kerberos authentication. For LogonUI, mstsc and cons ent modules, an anonymous NTLM authentication is performed, to retrieve the OS version. -dc-ip DC_IP, --dc-ip DC_IP IP Address of the domain controller -no-pass, --no-pass Do not prompt for password --tempdir TEMPDIR The name of the temporary directory to use for DLLs and output (Default: ThievingFox) --keepass Try to cleanup all poisonning artifacts related to KeePass.exe --keepass-share KEEPASS_SHARE The share on which KeePass is installed (Default: c$) --keepass-path KEEPASS_PATH The path where KeePass is installed, without the share name (Default: /Program Files/KeePass Password Safe 2/) --keepassxc Try to cleanup all poisonning artifacts related to KeePassXC.exe --keepassxc-path KEEPASSXC_PATH The path where KeePassXC is installed, without the share name (Default: /Program Files/KeePassXC/) --keepassxc-share KEEPASSXC_SHARE The share on which KeePassXC is installed (Default: c$) --mstsc Try to cleanup all poisonning artifacts related to mstsc.exe --consent Try to cleanup all poisonning artifacts related to Consent.exe --logonui Try to cleanup all poisonning artifacts related to LogonUI.exe --rdcman Try to cleanup all poisonning artifacts related to RDCMan.exe --mobaxterm Try to cleanup all poisonning artifacts related to MobaXTerm.exe --all Try to cleanup all poisonning artifacts related to all applications Collect For each application specified on the command line parameters, the collect module retrieves output files on the remote host stored inside C:WindowsTemp<tempdir> corresponding to the application, and decrypts them. The files are deleted from the remote host, and retrieved data is stored in client/ouput/. Multiple applications can be specified at once, or, the --all flag can be used to collect logs from all applications. $ python3 client/ThievingFox.py collect -husage: ThievingFox.py collect [-h] [-hashes HASHES] [-aesKey AESKEY] [-k] [-dc-ip DC_IP] [-no-pass] [--tempdir TEMPDIR] [--keepass] [--keepassxc] [--mstsc] [--consent] [--logonui] [--rdcman] [--mobaxterm] [--all] targetpositional arguments: target Target machine or range [domain/]username[:password]@<IP or FQDN>[/CIDR]options: -h, --help show this help message and exit -hashes HASHES, --hashes HASHES LM:NT hash -aesKey AESKEY, --aesKey AESKEY AES key to use for Kerberos Authentication -k Use kerberos authentication. For LogonUI, mstsc and consent modules, an anonymous NTLM authentication is performed, to retrieve the OS version. -dc-ip DC_IP, --dc-ip DC_IP IP Address of th e domain controller -no-pass, --no-pass Do not prompt for password --tempdir TEMPDIR The name of the temporary directory to use for DLLs and output (Default: ThievingFox) --keepass Collect KeePass.exe logs --keepassxc Collect KeePassXC.exe logs --mstsc Collect mstsc.exe logs --consent Collect Consent.exe logs --logonui Collect LogonUI.exe logs --rdcman Collect RDCMan.exe logs --mobaxterm Collect MobaXTerm.exe logs --all Collect logs from all applicationsDownload ThievingFox
ThievingFox - Remotely Retrieving Credentials From...
ThievingFox is a collection of post-exploitation tools to gather credentials from...
Source: KitPloit
Metasploit Weekly Wrap-Up 04/26/24

Rancher Modules This week, Metasploit community member h00die added the second of two modules targeting Rancher instances. These modules each leak sensitive information from vulnerable instances of the application which is intended to manage Kubernetes clusters. These are a great addition to Metasploit's coverage for testing Kubernetes environments. PAN-OS
Metasploit Weekly Wrap-Up 04/26/24
Rancher Modules
This week, Metasploit community member h00die added the second of...
Source: Rapid7 Blog
Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Results and Analysis

:::info This paper is available on arxiv under CC 4.0 license. Authors: (1) Zhe Liu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (2) Chunyang Chen, Monash University, Melbourne, Australia; (3) Junjie Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author; (4) Mengzhuo Chen, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (5) Boyu Wu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (6) Zhilin Tian, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (7) Yuekai Huang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (8) Jun Hu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (9) Qing Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author. ::: Table of Links Abstract and Introduction Motivational Study and Background Approach Experiment Design Results and Analysis Discussion and Threats to Validity Related Work Conclusion and References 5 RESULTS AND ANALYSIS 5.1 Bugs Detection Performance (RQ1) Table 2 presents the bug detection performance of InputBlaster. With the unusual inputs generated by InputBlaster, the bug detection rate is 0.78 (within 30 minutes), indicating 78 (28/36) of the bugs can be detected. In addition, the bugs can be detected with an average of 13.52 attempts, and the average bug detection time is 9.64 minutes, which is acceptable. This indicates the effectiveness of our approach in generating unusual inputs for testing the app, and facilitating the uncovering of bugs related to input widgets. Figure 5 demonstrates examples of InputBlaster's generated unusual inputs and the inputs that truly trigger the crash. We can see that our proposed approach can generate quite diversified inputs which mutate the valid input from different aspects, e.g., for the price in the first example which should be a non-negative value, the generated unusual inputs range from negative values and decimals to various kinds of character strings. Furthermore, it is good at capturing the contextual semantic information of the input widgets and their associated constraints, and generating the violations accordingly. For example, for the minimum and maximum price in the first example, it generates the unusual inputs with the minimum larger than the maximum, and successfully triggers the crash. We further analyze the bugs that could not be detected by our approach. A common feature is that they need to be triggered under specific settings, e.g., only under the user-defined setting, the input can trigger the crash, in the environment we tested, it may not have been possible to trigger a crash due to the lack of user-defined settings in advance. We have manually compared the unusual inputs generated by our approach with the ones in the issue reports. We find in all cases, InputBlaster can generate the satisfied buggy inputs within 30 attempts and 30 minutes, which further indicates its effectiveness. Performance comparison with baselines. Table 2 also shows the performance comparison with the baselines. We can see that our proposed InputBlaster is much better than the baselines, i.e., 136% (0.78 vs. 0.33) higher in bug detection rate (within 30 minutes) compared with the best baseline Text Exerciser. This further indicates the advantages of our approach. Nevertheless, the Text Exerciser can only utilize the dynamic hints in input generation which covers a small portion of all situations, i.e., a large number of input widgets do not involve such feedback. Without our elaborate design, the raw ChatGPT demonstrates poor performance, which further indicates the necessity of our approach. In addition, the string analysis methods, which are designed specifically for string constraints, would fail to work for mobile apps. In addition, since the input widgets of mobile apps are more diversified (as shown in Section 2.1.2) compared with the string, the heuristic analysis or finite-state automata techniques in the string analysis methods might be ineffective for our task. The baselines for automated GUI testing or valid text input generation are even worse, since their main focus is to increase the coverage through generating valid inputs. This further implies the value of our approach for targeting this unexplored task. 5.2 Ablation Study (RQ2) 5.2.1 Contribution of Modules. Table 3 shows the performance of InputBlaster and its 2 variants respectively removing the first and third module. In detail, for InputBlaster w/o valid Input (i.e., without Module 1), we provide the information related to the input widgets (as Table 1 P1) to the LLM in Module 2 and set other information from Module 1 as “null”. For InputBlaster w/o enrich Examples (i.e., without Module 3), we set the examples from Module 3 as “null” when querying the LLM. Note that, since Module 2 is for generating the unusual inputs which is indispensable for this task, hence we do not experiment with this variant. We can see that InputBlaster's bug detection performance is much higher than all other variants, indicating the necessity of the designed modules and the advantage of our approach. Compared with InputBlaster, InputBlaster w/o validInput results in the largest performance decline, i.e., 50% drop (0.39 vs. 0.78) in bug detection rate within 30 minutes. This further indicates that the generated valid inputs and inferred constraints in Module 1 can help LLM understand what the correct input looks like and generate the violated ones. InputBlaster w/o enrichExamples also undergoes a big performance decrease, i.e., 32% (0.53 vs. 0.78) in bug detection rate within 30 minutes, and the average testing time increases by 109% (9.64 vs. 20.15). This might be because without the examples, the LLM would spend more time understanding user intention and criteria for what kinds of answers are wanted. 5.2.2 Contribution of Sub-modules. Table 4 further demonstrates the performance of InputBlaster and its 5 variants. We remove each sub-module of the InputBlaster in Figure 3 separately, i.e., inferred constraint, mutation rule, text execution feedback, test generator and retrieved examples of buggy input. For removing the test generator, we directly let the LLM generate the unusual inputs, and for removing retrieved examples, we use the random selection method. For other variants, we set the removed content as “null”. The experimental results demonstrate that removing any of the sub-modules would result in a noticeable performance decline, indicating the necessity and effectiveness of the designed sub modules. Removing the mutation rules (InputBlaster w/o-mutateRule) have the greatest impact on the performance, reducing the bug detection rate by 50% (0.36 vs. 0.72 within 30 attempts). Remember that, InputBlaster first lets the LLM to generate the mutation rules (how to mutate the valid inputs), then asks it to produce the test generator following the mutation rule. With the generated mutation rules serving as the reasoning chain, the unusual input generation can be more effective, which further proves the usefulness of our design. We also notice that, when removing the test generator (InputBlaster w/o-generator), the bug detection rate does not drop much (0.72 vs. 0.61) when considering 30 attempts, yet it declines a lot (0.78 vs. 0.36) when considering 30 minutes of testing time. This is because our proposed approach lets the LLM produce the test generator which can yield a batch of unusual inputs. This means interacting with the LLM once can generate multiple outcomes. However, if asking the LLM to directly generates unusual inputs (i.e., InputBlaster w/o-generator), it requires interacting with LLM frequently, and could be quite inefficient. This further demonstrates we formulate the problem as producing the test generator task is efficient and valuable. In addition, randomly selecting the examples (InputBlaster w/oretriExample) would also largely influence the performance, and decrease the bug detection rate by 22% (0.56 vs. 0.72 within 30 attempts). This indicates that by providing similar examples, the LLM can quickly think out what should the unusual inputs look like. Nevertheless, we can see that, compared with the variant without enriched examples in prompt (Table 3), the randomly selected examples do take effect (0.47 vs 0.56 in bug detection rate within 30 attempts), which further indicates the demonstration can facilitate the LLM in producing the required output. 5.2.3 Influence of Different Number of Examples. Table 5 demonstrates the performance under the different number of examples provided in the prompt. We can see that the number of detected bugs increases with more examples, reaching the highest bug detection rate with 5 examples. And after that, the performance would gradually decrease even increasing the examples. This indicates that too few or too many examples would both damage the performance, because of the tiny information or the noise in the provided examples. 5.3 Usefulness Evaluation (RQ3) Table 6 shows all bugs spotted by Ape integrated with our InputBlaster, and more detailed information on detected bugs can be seen in our website. For the 131 apps, InputBlaster detects 43 bugs in 32 apps, of which 37 are newly-detected bugs. Furthermore, these new bugs are not detected by the Ape without InputBlaster. We submit these 37 bugs to the development team, and 28 of them have been fixed/confirmed so far (21 fixed and 7 confirmed), while the remaining are still pending (none of them is rejected). This further indicates the effectiveness and usefulness of our proposed InputBlaster in bug detection. When confirming and fixing the bugs, some Android app developers express thanks such as “Very nice! You find an invalid input we thought was too insignificant to cause crashes.”(i.e., Ipsos). Furthermore, some developers also express their thought about the buggy text input “Handling different inputs can be tricky, and I admit we couldn't test for every possible scenario. It has given me a fresh appreciation for the complexity of user inputs and the potential bugs they can introduce. ”(i.e., DRBUs). Some developers also present valuable suggestions to facilitate the further improvement of InputBlaster. For example, some of them hope that we can find the patterns of these bugs and design repair methods.
Leveraging LLMs for Generation of Unusual Text Inputs...
:::info
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Zhe...
Source: Hacker Noon